
Cómo construí un segundo cerebro mantenido por IA: arquitectura, esquema y lecciones aprendidas
¿Cuántas veces has guardado un artículo interesante para no volver a encontrarlo nunca? ¿O has tenido una idea que sabías que conectaba con algo que leíste hace tres semanas, pero no recuerdas dónde?
Ese es el problema que quería resolver: no capturar más, sino conectar mejor. Las herramientas de notas tradicionales acumulan; no piensan. Y los LLMs saben mucho del mundo, pero no saben nada de ti ni de lo que has leído esta semana.
Este post documenta cómo construí un sistema que resuelve exactamente esa tensión: un vault de Obsidian cuyo grafo de conocimiento es mantenido activamente por un agente de IA. No es «IA encima de tus notas» — es un sistema donde el agente es el mantenedor, con un esquema explícito que define cómo opera y que evoluciona con el uso.
Lo llamo LLM Wiki — un término acuñado por Andrej Karpathy, cuyo documento fundacional describe exactamente este patrón y fue el punto de partida de todo lo que sigue.
El patrón: LLM Wiki
La idea central es simple:
captura (inbox/ · mis_notas/) ↓ agente procesa ←── CLAUDE.md (esquema operativo) ↓sources / entities / concepts / synthesis (wiki mantenida) ↓ Obsidian Graph View (exploración visual) ↓ index.base (índice dinámico por tipo)
Las fuentes externas (artículos, clippings) son inmutables — el agente nunca las modifica. Las lee, extrae lo relevante y genera páginas de síntesis, entidades y conceptos. Las notas propias (ideas, reflexiones, bitácoras de proyecto) se vinculan al grafo existente.
El resultado es una red que crece en coherencia con cada sesión, no solo en volumen.
Stack: Obsidian como interfaz de lectura, escritura y visualización + Claude Code como agente mantenedor.
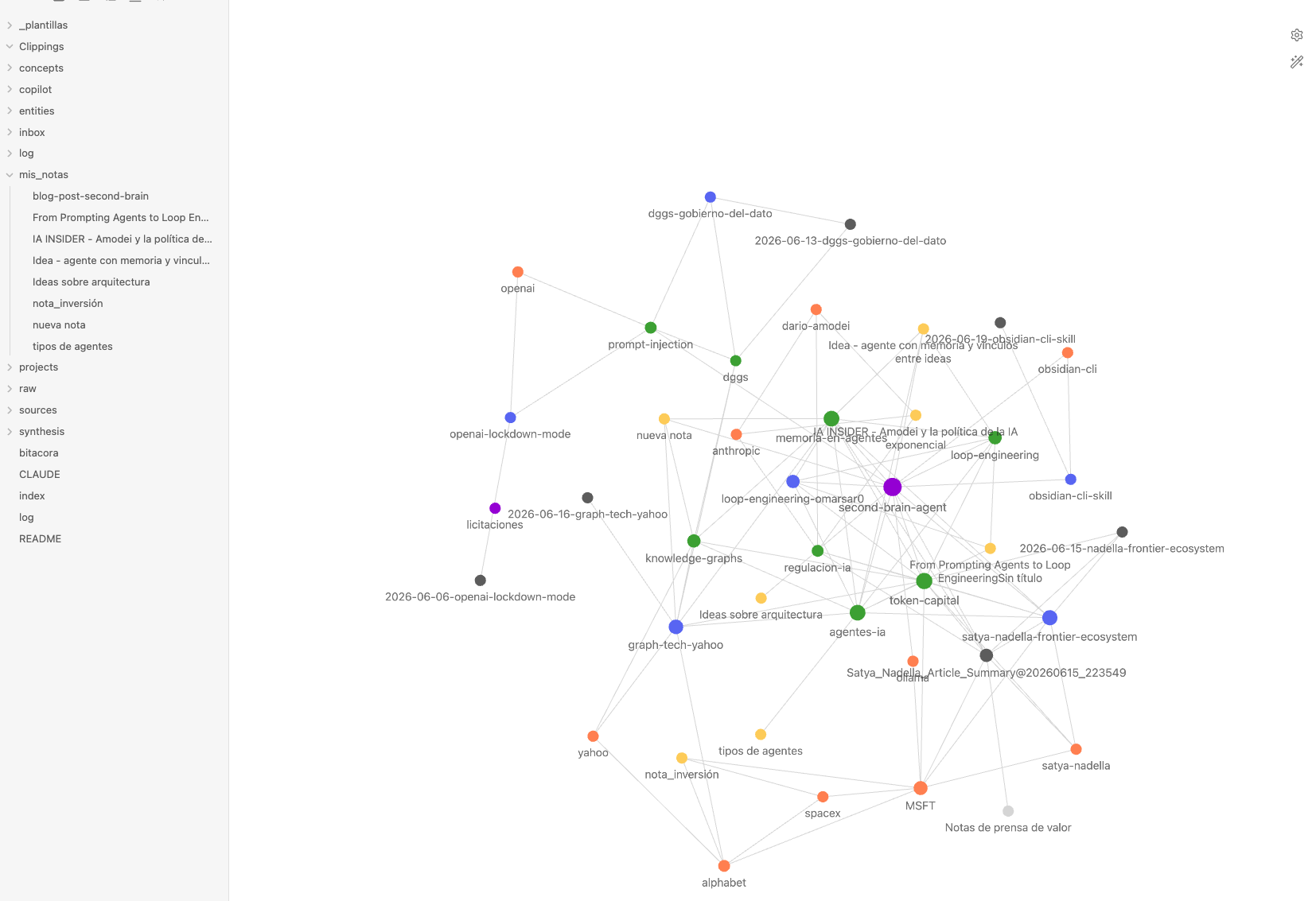
La pieza clave: CLAUDE.md como esquema operativo
Todo el comportamiento del agente está definido en un único archivo: CLAUDE.md. No es documentación para humanos — es el sistema de instrucciones que el agente carga al inicio de cada sesión y que gobierna cada decisión que toma.
second_brain/├── CLAUDE.md ← esquema operativo del agente├── README.md ← guía de uso para el humano├── index.base ← índice dinámico (Obsidian Bases)├── log/│ └── 2026-06.md ← registro mensual de operaciones├── inbox/ ← punto de captura unificado├── raw/clippings/ ← fuentes originales — INMUTABLE├── sources/ ← resúmenes de cada fuente ingerida├── entities/ ← empresas, personas, productos, tecnologías├── concepts/ ← ideas conceptuales y marcos de referencia├── synthesis/ ← ensayos de síntesis multi-fuente├── projects/ ← proyectos con bitácora└── mis_notas/ ← notas propias procesadas
El CLAUDE.md define:
- Los principios que gobiernan cada decisión (mínima fricción al capturar, inferencia conservadora, todo se cita)
- El frontmatter exacto para cada tipo de nota
- El orden del barrido (qué carpetas escanear y en qué orden)
- Los workflows de cada operación (ingesta, barrido, lint, síntesis)
- Las reglas de inferencia (cuándo crear un enlace en firme vs. marcarlo como candidato)
La clave: cuando algo no funciona, no cambio la conversación — cambio el CLAUDE.md. El esquema se co-evoluciona con el uso. La próxima sesión parte del aprendizaje acumulado.
Frontmatter tipado: la base de todo
Cada nota del vault lleva un bloque YAML con campos semánticos. No es decorativo — es la señal que permite al agente clasificar, buscar y vincular sin ambigüedad.
El campo más importante es tipo:, que determina cómo procesa el agente la nota:
# Una fuente externa procesadatipo: fuenteorigen: "[[2026-06-15-nadella-frontier-ecosystem]]"fecha: 2026-06-15tags: [tipo/fuente, ia, token-capital, ecosistema]relacionado: ["[[token-capital]]", "[[MSFT]]", "[[satya-nadella]]"]
# Un concepto extraído de varias fuentestipo: conceptotags: [tipo/concepto, concepto]relacionado: ["[[agentes-ia]]", "[[memoria-en-agentes]]", "[[claude-ai]]"]
# Una idea propiatipo: ideafecha: 2026-06-07tags: [tipo/idea, agentes-ia, memoria]relacionado: ["[[memoria-en-agentes]]", "[[second-brain-agent]]"]estado: enlazado # nuevo → enlazado → revisado
El campo estado es la señal de tracking: el agente busca notas con estado: nuevo durante el barrido y las procesa. Una vez enlazadas, pasan a estado: enlazado.
El tag estructural para el Graph View
Cada nota lleva además un tag tipo/x como primer elemento de su array. Este tag es exclusivamente visual: colorea el grafo de Obsidian por tipo de nodo.
{ "query": "tag:#tipo/concepto", "color": { "a": 1, "rgb": 3973171 } },{ "query": "tag:#tipo/entidad", "color": { "a": 1, "rgb": 16744272 } },{ "query": "tag:#tipo/fuente", "color": { "a": 1, "rgb": 5793266 } },{ "query": "tag:#tipo/sintesis", "color": { "a": 1, "rgb": 14443650 } }

Las cuatro operaciones del agente
El agente opera mediante cuatro comandos que se pueden combinar (barrido + ingesta, lint + barrido, etc.):
barrido
Escanea el vault buscando contenido nuevo o sin procesar. Orden: inbox/ → mis_notas/ → resto del vault.
Para cada nota sin frontmatter o con estado: nuevo:
- Infiere el tipo (¿idea propia? ¿clipping externo? ¿bitácora?)
- Añade el frontmatter mínimo
- Busca páginas relacionadas y crea enlaces
- Si la relación es dudosa → la marca como «enlace candidato» en lugar de forzarla
- Si la nota estaba en
inbox/o en la raíz → la mueve amis_notas/tras procesarla
El principio de inferencia conservadora es central: el agente prefiere anotar una relación como «candidato a confirmar» antes que inventar un vínculo. La wiki debe poder confiarse.
ingesta
Procesa fuentes externas (artículos, clippings):
inbox/ o Clippings/ → sources/<slug>.md + entities/ + concepts/ → raw/clippings/ (archivo histórico inmutable)
Por ejemplo, al ingerir el artículo de Satya Nadella sobre ecosistemas de IA, el agente genera automáticamente:
Tesis centralLa ventaja competitiva no está en elegir el mejor modelo, sino en construirun bucle de aprendizaje donde el capital humano y el token capital secomponen mutuamente. Relaciones con el vault [token-capital] — concepto central introducido aquí [memoria-en-agentes] — el "knowledge base" institucional es exactamente el problema que resuelve un agente de memoria
lint
Mantenimiento periódico. Revisa: enlaces candidatos pendientes, páginas huérfanas, contradicciones entre páginas, conceptos sin página propia. Al final, propone síntesis para temas con ≥ 3 fuentes.
síntesis: <tema>
Cuando un tema alcanza masa crítica, el agente propone antes de crear:
Propuesta de síntesis: "El estado del arte de agentes IA (2026)"- Fuentes: [[tipos-de-agentes-claude]], [[loop-engineering-omarsar0]], [[graph-tech-yahoo]]- Tesis: el trabajo del ingeniero sube un nivel — de diseñar agentes a diseñar los loops que los promptean- Estructura tentativa: taxonomía → anatomía del loop → economía → casos de uso¿Procedo?
El agente propone; el humano aprueba. Sin aprobación, no crea nada.
Las 5 mejoras que surgieron del uso real
La arquitectura inicial fue sencilla. Estos cinco problemas emergieron rápido:
1. inbox/ como punto de captura unificado
Problema: las notas aterrizaban en la raíz, en mis_notas/, en Clippings/… el agente buscaba por todo el vault en cada sesión.
Solución: inbox/ que el agente escanea primero. Las notas procesadas se mueven a mis_notas/ automáticamente.
2. Pipeline de clippings simplificado
Problema: el flujo original tenía dos pasos intermedios innecesarios y fricción para el usuario.
Solución: el agente procesa directamente desde donde llega el contenido a sources/. raw/clippings/ es el archivo histórico, pero ya no es un paso obligatorio.
3. Rotación mensual del log
Problema: log.md crecía indefinidamente.
Solución: archivos mensuales en log/YYYY-MM.md. log.md pasa a ser un índice de punteros.
4. index.md → index.base (Obsidian Bases)
Problema: el agente mantenía el índice a mano — fuente de errores y trabajo innecesario.
Solución: 6 vistas dinámicas (Fuentes, Conceptos, Entidades, Proyectos, Síntesis, Ideas) que consultan el frontmatter automáticamente. El agente ya no toca el índice.
5. synthesis/ para síntesis multi-fuente
Problema: concepts/ tiene páginas de un solo concepto. Cuando acumulas 3+ fuentes sobre un tema, merece un ensayo que cruce perspectivas.
Solución: carpeta synthesis/ con tipo: sintesis y color propio en el Graph View.
Lo que escala bien y lo que no
Escala bien: index.base dinámico, rotación mensual del log, obsidian search indexado, inbox/ como captura acotada.
Lo que se rompe primero:
| Umbral | Problema | Fix |
|---|---|---|
| ~200 notas | Páginas de concepto con listas de menciones inmanejables | Backlinks dinámicos vía Obsidian Bases |
| ~300 notas | Barrido full-vault lento | Confiar solo en inbox/ + estado: nuevo |
| ~500 notas | Coherencia global degrada | Sesiones temáticas acotadas en lugar de operaciones globales |
El riesgo estructural: los LLMs tienen contexto finito. A partir de cierto volumen, la coherencia se mantiene localmente (en la sesión) pero no globalmente. La respuesta es acotar el scope de cada sesión, no intentar procesar todo el vault de una vez.
Lecciones clave
Después de varias semanas usando este sistema, estas son las conclusiones que llevaría a cualquier implementación similar:
- El esquema es el producto. La calidad del segundo cerebro depende casi enteramente del
CLAUDE.md, no del modelo ni de la herramienta. Un esquema claro convierte cualquier LLM capaz en un mantenedor confiable. - La inferencia conservadora es más valiosa que la exhaustiva. Un enlace marcado como «candidato a confirmar» vale más que diez enlaces inventados. La confianza en el sistema depende de que sus afirmaciones sean verificables.
- El esquema debe co-evolucionar con el uso. Cuando algo produce un resultado inesperado, el insight va al
CLAUDE.md, no solo a la conversación. Así la próxima sesión parte del aprendizaje acumulado. - La mínima fricción al capturar es no negociable. Si el sistema requiere esfuerzo para añadir notas, dejarás de añadirlas. El agente debe poder inferir razonablemente y enlazar después.
- Dos vaults especializados > un vault generalista. Mezclar contenido técnico con recetas o películas degrada la calidad de los enlaces — el agente pierde contexto semántico coherente.
- El dominio importa. El agente hace mejores inferencias cuando el vault tiene coherencia semántica. Una sola carpeta bien definida supera a diez carpetas mezcladas.
Preguntas frecuentes
¿Necesito saber programar para montar esto?
No. El único «código» que escribes es el CLAUDE.md en texto plano. Claude Code maneja la interacción con Obsidian vía su CLI oficial.
¿Cuánto tiempo lleva cada sesión de mantenimiento?
Un barrido con 2-3 notas nuevas tarda menos de un minuto. Una sesión de lint completa, dependiendo del volumen, entre 5 y 15 minutos. La cadencia habitual es un barrido al capturar algo nuevo y un lint mensual.
¿Qué pasa si el agente enlaza algo incorrectamente?
El campo estado: enlazado no es irreversible. Los enlaces candidatos están marcados explícitamente para revisión humana. El lint periódico detecta inconsistencias. Y el CLAUDE.md puede ajustarse para que el agente sea más o menos conservador.
¿Es seguro tener el vault en GitHub público?
No directamente. raw/clippings/ contiene copias de artículos (copyright), y mis_notas/ tiene contenido personal. La recomendación es un repositorio separado tipo «template» con solo la estructura, el CLAUDE.md y ejemplos anonimizados.
¿Funciona con otros LLMs además de Claude?
El esquema en CLAUDE.md es agnóstico al modelo — cualquier LLM suficientemente capaz puede seguirlo. Claude Code es la herramienta de ejecución, pero el patrón es portable.
¿Qué diferencia hay entre sources/ y synthesis/?sources/ es un resumen de una fuente externa con sus relaciones. synthesis/ es un ensayo que cruza varias fuentes sobre un mismo tema, con tesis propia. Una synthesis/ necesita ≥ 3 fuentes y aprobación explícita del usuario antes de crearse.
Referencias y recursos
- LLM Wiki — Andrej Karpathy — el documento fundacional del patrón. Karpathy describe exactamente esta arquitectura: fuentes inmutables, wiki compilada por el LLM, y un esquema que define estructura y workflows. Todo lo que se documenta en este post parte de ahí.
- Obsidian — la herramienta de notas base
- Claude Code — el agente mantenedor
- Obsidian CLI — la interfaz de línea de comandos que usa el agente para operar el vault sin romper wikilinks
- Obsidian Bases — vistas dinámicas sobre frontmatter (el reemplazo de
index.md) - Building a Second Brain — Tiago Forte, el marco conceptual original del que parte este sistema
- «From Prompting Agents to Loop Engineering» — @omarsar0, el artículo que introdujo el concepto de loop engineering en el vault
- «A frontier without an ecosystem is not stable» — Satya Nadella, donde aparece el concepto de token capital
¿Y tú qué sistema usas?
Este vault lleva pocas semanas rodando y ya está cambiando cómo capturo y conecto ideas. Pero seguro que hay enfoques que no he considerado.
¿Tienes un sistema de notas conectado? ¿Has probado a darle mantenimiento con un agente? Cuéntamelo en los comentarios — me interesa especialmente saber cómo resuelves el problema del volumen y la coherencia a largo plazo.
Y si quieres replicar esta arquitectura o tienes dudas sobre alguna parte del sistema, escríbeme directamente.
Este post es parte de una serie sobre el proyecto second-brain-agent — la construcción en curso de un sistema de conocimiento personal mantenido por IA.Cómo construí un segundo cerebro mantenido por IA: arquitectura, esquema y lecciones aprendidas
Llevo años con el mismo problema: capturo artículos, ideas y notas, pero la colección crece sin conectarse. Los sistemas de notas acumulan, no piensan. Y los LLMs saben mucho del mundo, pero no saben nada de ti.
Este post documenta cómo resolví esa tensión construyendo lo que llamo un LLM Wiki: un vault de Obsidian cuyo grafo de conocimiento es mantenido activamente por un agente de IA. No es un sistema de notas con IA encima — es un sistema donde el agente es el mantenedor, con un schema explícito que define exactamente cómo opera
