
Trabajando con Datetime y Time

Hemos preparado un código para bajar datos de la actividad comercial de mayoristas en Mercamadrid. Estos datos se pueden bajar desde este link del portal de datos abiertos del Ayuntamiento de Madrid.
La información esta estructura en una serie de campos tales como:
He intentado gestionar y minimizar el tamaño del pandas con el modelo propuesto por Matt Harrison, estoy haciendo un esfuerzo para seguir el «chaining» siempre que sea posible.
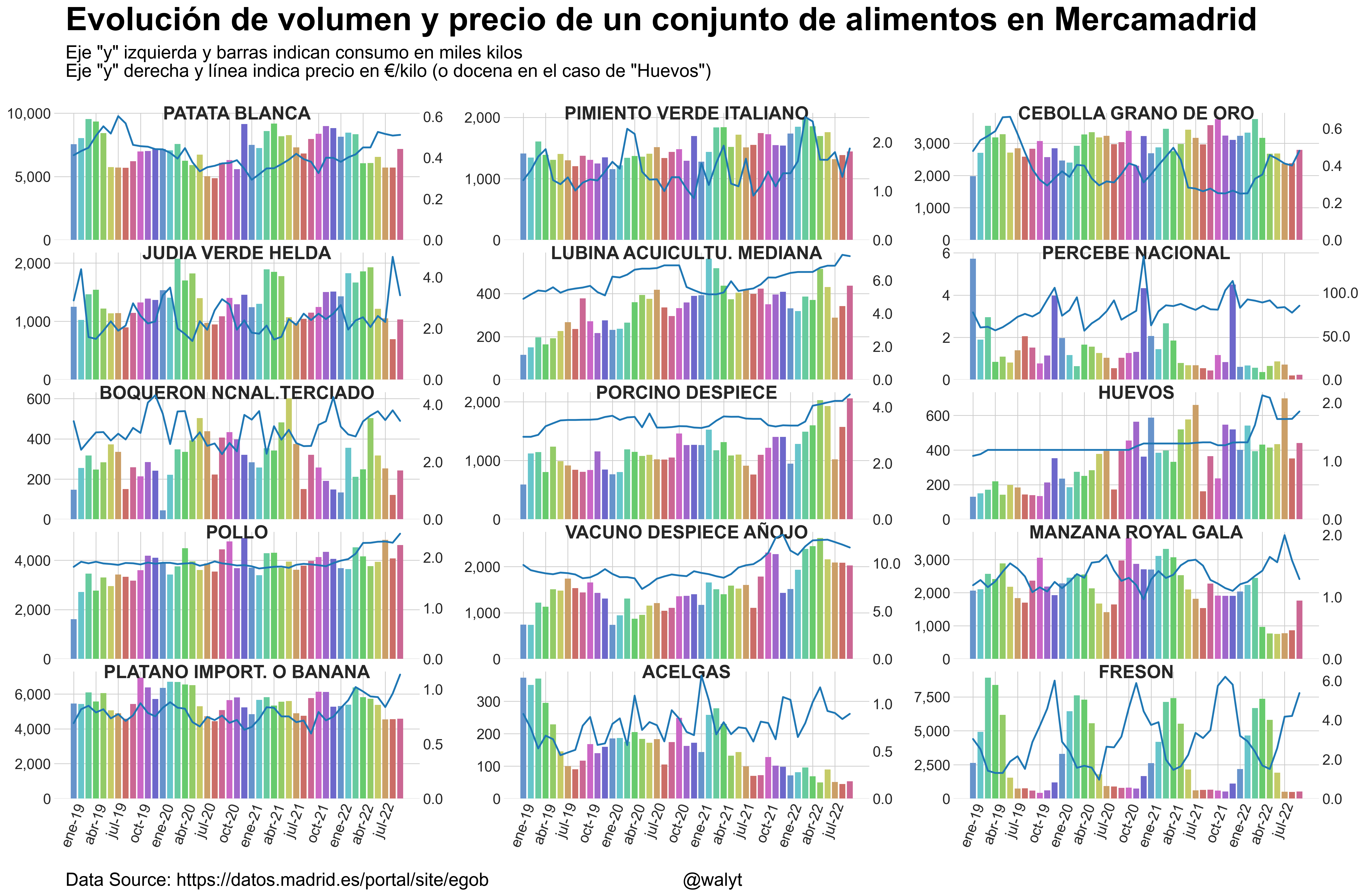
Presentamos el código necesario para bajar y preparar adecuadamente la información desde su repositorio en datos Madrid, y preparamos una rejilla de datos con los mismos..
En cada subgráfica, una por cada producto, presentamos la evolución del consumo como barras (eje «y» izquierda) )y la evolución de precios (eje «y» derecha). Para claridad se han codificado las barras según temperatura del mes..

Vamos a enumerar las principales leyes lógicas que nos permiten trabajar sobre expresiones complejas con varias proposiciones. Básicamente son leyes que rigen la Lógica Proposicional. Las enumeramos agrupadas según el número de proposiciones, añadiendo un último bloque con las condicionales.
La lista de leyes está basada en el primer capítulo del libro «Lenguaje matemático: conjuntos y números» de los autores Miguel Delgado Pineda y María José Muñoz Bouzo.
Leer más »
En este ejercicio vamos a estudiar como se relacionan modelos a priori estancos como un simple Bernouilli con la distribución exponencial. Como pensando en sucesos singulares, que se repiten en el tiempo, podemos llegar a entender la distribución de los tiempos de espera entre esos sucesos. Empecemos…
Leer más »En este trabajo vamos a estudiar las dos aproximaciones más conocidas en los métodos de inferencia estadística: el método bayesiano y el frecuentista. Un búsqueda rápida en Google confirma el gran número de interesantes discusiones al respecto. Personalmente me decanto por el Bayesiano, al final de este trabajo explicaré por qué.


Vamos a preparar un script que nos permita evaluar las variaciones que hay en los cambios de moneda, y nos de una idea de que riesgos estamos corriendo cuando fijamos los cambios. Las series históricas las sacamos de la libreria https://pypi.org/project/investpy/ (construída por Álvaro Bartolomé del Canto @alvarob96 at GitHub) que obtiene los datos de la web de información financiera http://www.investing.com
Leer más »
Licencia : https://creativecommons.org/licenses/by-nc-sa/4.0/
Empecemos con el uso «estandar» del Teorema. Lo vamos a aplicar a un problema clásico, el de las bolsas con bolas de colores:
Leer más »Sean dos bolsas indistinguibles, la primera, llamémosla bolsa 1, tiene 4 bolas verdas y una bola roja, la segunda, llamémosla bolsa 2, tiene 2 bolas verdes y tres bolas rojas. Se elije al azar una de las bolsas y obtenemos una bola verde, ¿qué probabilidad hay de que esta venga de la bolsa 1?
