Cómo construí un segundo cerebro mantenido por IA: arquitectura, esquema y lecciones aprendidas
¿Cuántas veces has guardado un artículo interesante para no volver a encontrarlo nunca? ¿O has tenido una idea que sabías que conectaba con algo que leíste hace tres semanas, pero no recuerdas dónde?
Ese es el problema que quería resolver: no capturar más, sino conectar mejor. Las herramientas de notas tradicionales acumulan; no piensan. Y los LLMs saben mucho del mundo, pero no saben nada de ti ni de lo que has leído esta semana.
Este post documenta cómo construí un sistema que resuelve exactamente esa tensión: un vault de Obsidian cuyo grafo de conocimiento es mantenido activamente por un agente de IA. No es «IA encima de tus notas» — es un sistema donde el agente es el mantenedor, con un esquema explícito que define cómo opera y que evoluciona con el uso.
Lo llamo LLM Wiki — un término acuñado por Andrej Karpathy, cuyo documento fundacional describe exactamente este patrón y fue el punto de partida de todo lo que sigue.
Leer más »
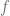 , que tiene como dominio
, que tiene como dominio  y de igual manera tiene como imagen
y de igual manera tiene como imagen  . Es esta una función muy básica: puede dar siempre el mismo valor, ya sea 0 ó 1, a cualquier valor de entrada, o por el contrario puede ofrecer una valor diferente segun sea el valor de x. Llamaremos constantes al primer tipo de función, y balanceadas al segundo.
. Es esta una función muy básica: puede dar siempre el mismo valor, ya sea 0 ó 1, a cualquier valor de entrada, o por el contrario puede ofrecer una valor diferente segun sea el valor de x. Llamaremos constantes al primer tipo de función, y balanceadas al segundo. , de que tipo es.
, de que tipo es. o
o  , en una superposición de los mismos. Veamos los detalles.
, en una superposición de los mismos. Veamos los detalles.