Análisis de la planta de Taxis de Madrid
Vamos a analizar el fichero de «Taxis»del Ayuntamiento de Madrid, con información sacada del portal de OpenData : https://datos.madrid.es/portal/site/egob/menuitem.c05c1f754a33a9fbe4b2e4b284f1a5a0/?vgnextoid=4f16216612d39410VgnVCM2000000c205a0aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCRD
Como siempre importamos las librerias necesarias : pandas, numpy, matplotlib,datetime..y añadimos calendar. Usaremos esta última para sacar el literal de un mes según su nº de orden.
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import datetime
import matplotlib.dates as mdates
%matplotlib inline
import matplotlib.ticker as mtick
from matplotlib.ticker import FuncFormatter from mpl_toolkits.mplot3d import Axes3D
import calendar
pd.options.display.float_format = '{:,.1f}'.format
Preparamos una texto para incluirlo en cada gráfico como fuente…
fuente='Fuente : Ayuntamiento de Madrid, http://datos.madrid.es'
Construimos la URL de la fuente de datos :
path_web='https://datos.madrid.es/egob/catalogo/300219-0-taxi-flota.csv'
Leemos los datos desde su localizacion en ‘path_web’, en este fichero tenemos los datos de Junio de 2018.
taxis=pd.read_csv(path_web,sep=";",encoding='windows-1250',index_col=False)
Vemos unos ejemplos de lineas para asegurar que todo ha ido bien. Podemos chequear también las columnas
len(taxis)
15652
taxis.describe()
| CĂłdigo | Cilindrada | |
|---|---|---|
| count | 15,652.0 | 15,652.0 |
| mean | 1,348,913.2 | 1,687.2 |
| std | 100,096.0 | 171.3 |
| min | 550,016.0 | 0.0 |
| 25% | 1,269,989.8 | 1,598.0 |
| 50% | 1,346,296.5 | 1,598.0 |
| 75% | 1,433,151.5 | 1,798.0 |
| max | 1,514,196.0 | 3,498.0 |
«`python
taxis.columns
«`
Index([‘Código’, ‘Matrícula’, ‘Fecha Matriculación’, ‘Marca’, ‘Modelo’, ‘Tipo’,
‘Variante’, ‘Clasificación medioambiental’, ‘Combustible’, ‘Cilindrada’,
‘Potencia’, ‘Número de Plazas’,
‘Fecha inicio de prestación del servicio de taxi’, ‘Eurotaxi’,
‘Régimen Especial de Eurotaxi’,
‘Fecha inicio Régimen Especial Eurotaxi’,
‘Fecha fin Régimen Especial Eurotaxi’, ‘Fecha’],
dtype=’object’)
Nos aseguraremos de que la columna ‘Fecha Matriculacíon’ tiene el formato Datetime para trabajos posteriores, y la ordenamos a continuación
taxis['Fecha Matriculación']=pd.to_datetime(taxis['Fecha Matriculación'],format='%d/%m/%Y')
taxis=taxis.sort_values(['Fecha Matriculación'])
Busquemos el Taxi con la matrícula más antigua :
print ('Matricula {} de fecha {}'.format(taxis['Matrícula'].iloc[0],taxis['Fecha Matriculación'].iloc[0].strftime('%d/%m/%Y')))
Matricula 2239DTJ de fecha 13/12/2005
..y con la matrícula más moderna :
print ('Matricula {} de fecha {}'.format(taxis['Matrícula'].iloc[-1],taxis['Fecha Matriculación'].iloc[-1].strftime('%d/%m/%Y')))
Matricula 8333KLS de fecha 12/06/2018
Calculemos la lista de número de Taxis por Marca
fig = plt.figure(1, (6,4))
ax = fig.add_subplot(1,1,1)
ax=taxis['Marca'].value_counts().plot.bar()
ax.locator_params(axis='y',nbins=10)
ax.set_xlabel('Marca')
ax.set_ylabel('Número de coches',size=16)
ax.grid(axis='y')
ax.set_title('Nº de Taxis por Marca')
fig.suptitle(fuente,size=10,x=0,y=-.4)
fig.savefig('Taxis por Marca',bbox_inches = 'tight')

..ahora ordenaremos por combustible usado
fig = plt.figure(1, (6,4))
ax = fig.add_subplot(1,1,1)
ax=taxis['Combustible'].value_counts().plot.bar()
ax.locator_params(axis='y',nbins=10)
ax.set_xlabel('Combustible')
ax.set_ylabel('Número de coches',size=16)
ax.grid(axis='y')
ax.set_title('Nº de Taxis por Combustible')
fig.suptitle(fuente,size=10,x=0,y=-.4)
fig.savefig('Taxis por Marca',bbox_inches = 'tight')

Ahora trabajemos estos dos últimos campos de manera conjunta. Empezamos con un ‘groupby’ por estos dos campos, añadiendo ‘size()’ para que nos calcule el tamaño de cada campo :
tabla=taxis.groupby([taxis['Marca'],taxis['Combustible']]).size()
tabla
Marca Combustible
CHEVROLET DIESEL 7
GASOLINA TRANSFORMADO GLP 1
CITROEN DIESEL 340
GLP / GASOLINA 345
DACIA DIESEL 281
GLP / GASOLINA 896
FIAT DIESEL 54
GLP / GASOLINA 276
FORD DIESEL 145
GASOLINA-ELECTRICIDAD 4
HYUNDAI DIESEL 7
MERCEDES-BENZ DIESEL 199
GASOLINA – GAS NATURAL 9
GASOLINA TRANSFORMADO GLP 1
NISSAN ELECTRICO 13
OPEL DIESEL 1
PEUGEOT DIESEL 992
PEUGEOT DIESEL 1
RENAULT DIESEL 134
SEAT DIESEL 1875
GASOLINA – GAS NATURAL 199
GASOLINA TRANSFORMADO GLP 48
GLP / GASOLINA 612
SKODA DIESEL 4412
GASOLINA TRANSFORMADO GLP 14
GLP / GASOLINA 207
SSANGYONG GASOLINA 6
GASOLINA TRANSFORMADO GLP 1
GLP / GASOLINA 6
TOYOTA GASOLINA-ELECTRICIDAD 4067
VOLKSWAGEN DIESEL 478
GASOLINA – GAS NATURAL 21
dtype: int64
Ya tenemos la tabla lista, ahora vamos a representarla. He encontrado este modelo de mapa de temperatura de SeaBorn que queda muy bien :
tabla=tabla.reset_index()
import seaborn as sns
sns.set()
matriz=tabla.pivot('Marca','Combustible',0)
f, ax = plt.subplots(figsize=(15, 6))
sns.heatmap(matriz, fmt=".0f", annot=True,linewidths=1, ax=ax, cmap="YlGnBu")
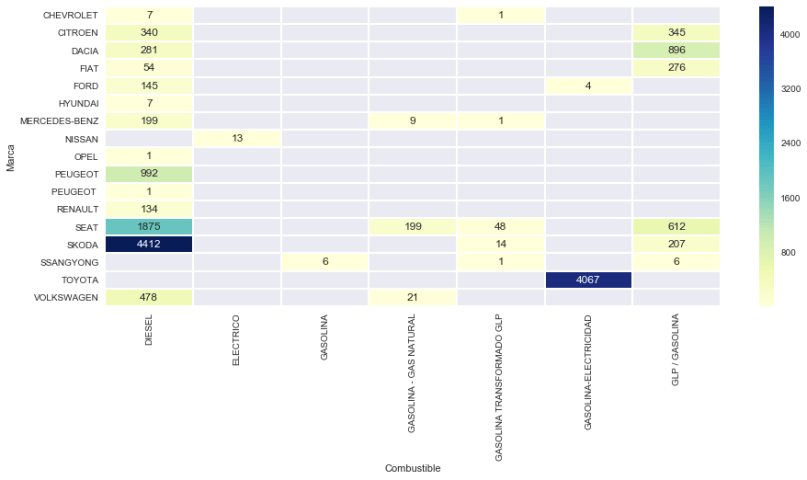
Insertemos ahora una columna con la antigüedad de cada Matricula, simplemente calculando la diferencia entre ‘ahora’ y la fecha de matriculación, que vendrá en días (.days) y la pasamos a años equivalentes dividiendo por 365 (nos olvidamos de los bisiestos!)
ahora=datetime.datetime.today() taxis['antiguedad']=taxis['Fecha Matriculación'].apply(lambda x : (ahora-x).days/365)
A continuación representamos una gráfica con el nº de matriculaciones ordenadas por meses :
fig = plt.figure(1, (15,6))
ax = fig.add_subplot(1,1,1)
data_series=taxis.groupby([taxis['Fecha Matriculación'].dt.year,taxis['Fecha Matriculación'].dt.month]).size()
ax.set_xlabel('Marca')
ax.set_ylabel('Número de coches',size=16)
ax.grid(axis='y')
ax.set_title('Nº de Matriculaciones de Taxis por mes')
bar_width=0.8
opacity=1
error_config = {'ecolor': '0.3'}
rects1 = ax.bar(np.arange(len(data_series.index.tolist())), data_series.values,bar_width,alpha=opacity)
def format_func(value, tick_number):
anno,mes=data_series.index.tolist()[int(value)]
mes=calendar.month_abbr[mes]
return mes+'-'+str(anno)[-2:]
ax.xaxis.set_major_formatter(plt.FuncFormatter(format_func))
# Preparamos una lista con los tickts que nos interesan : el primero, el último y todos los meses Enero y Julio
lista_ticks=[]
lista_ticks=[i for i in np.arange(3,len(data_series.index.tolist())) if data_series.index[i][1] in (1,7)]
lista_ticks.extend([0,len(data_series)-1]) #añade el primero y el último
ax.xaxis.set_ticks(lista_ticks)
fig.suptitle(fuente,size=15,x=0.5,y=0)
fig.savefig('matriculas por mes',bbox_inches = 'tight')
plt.show()
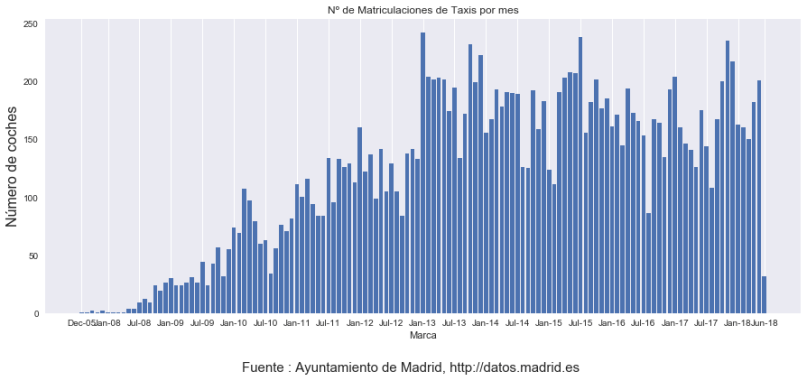
Utilicemos el campo ‘antiguedad’ para un par de cálculos y para generar una gráfica :
'Antiguedad media del parque de taxis : {:.1f} años, con desviación +/-{:.1f} años'.format(taxis['antiguedad'].mean(),taxis['antiguedad'].std())
‘Antiguedad media del parque de taxis : 4.0 años, con desviación +/-2.4 años’
Se nos ocurre generar una gráfica con la antigüedad media por Marca :
taxis.groupby(['Marca'])['antiguedad'].describe().sort_values(by='mean',ascending=False)
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Marca | ||||||||
| HYUNDAI | 7.0 | 8.7 | 0.5 | 8.2 | 8.4 | 8.8 | 8.9 | 9.5 |
| OPEL | 1.0 | 8.7 | nan | 8.7 | 8.7 | 8.7 | 8.7 | 8.7 |
| CHEVROLET | 8.0 | 8.1 | 0.3 | 7.7 | 7.8 | 8.0 | 8.4 | 8.5 |
| PEUGEOT | 1.0 | 6.4 | nan | 6.4 | 6.4 | 6.4 | 6.4 | 6.4 |
| SKODA | 4,633.0 | 5.0 | 2.4 | 0.5 | 2.9 | 5.0 | 6.8 | 12.6 |
| RENAULT | 134.0 | 4.9 | 1.8 | 0.2 | 4.4 | 5.2 | 6.2 | 8.8 |
| TOYOTA | 4,067.0 | 4.4 | 2.5 | 0.1 | 2.2 | 4.9 | 6.5 | 10.4 |
| MERCEDES-BENZ | 209.0 | 4.1 | 2.3 | 0.2 | 2.7 | 3.6 | 5.1 | 10.0 |
| SEAT | 2,734.0 | 3.9 | 2.0 | 0.1 | 2.4 | 4.2 | 5.1 | 11.0 |
| VOLKSWAGEN | 499.0 | 3.7 | 2.6 | 0.1 | 0.9 | 3.6 | 4.9 | 10.0 |
| PEUGEOT | 992.0 | 3.3 | 1.7 | 0.5 | 2.2 | 3.1 | 4.2 | 9.5 |
| DACIA | 1,177.0 | 2.4 | 1.0 | 0.1 | 1.5 | 2.8 | 3.2 | 3.8 |
| NISSAN | 13.0 | 2.1 | 0.7 | 1.0 | 2.0 | 2.0 | 2.2 | 3.8 |
| CITROEN | 685.0 | 2.0 | 1.1 | 0.1 | 1.2 | 2.0 | 2.7 | 9.3 |
| FIAT | 330.0 | 0.8 | 1.2 | 0.1 | 0.3 | 0.5 | 0.9 | 9.7 |
| FORD | 149.0 | 0.8 | 0.5 | 0.1 | 0.5 | 0.6 | 0.9 | 2.6 |
| SSANGYONG | 13.0 | 0.4 | 0.2 | 0.1 | 0.2 | 0.5 | 0.6 | 0.7 |
«`python
taxis.groupby([‘Marca’])[‘antiguedad’].mean().sort_values(ascending=False).plot.bar()
«`
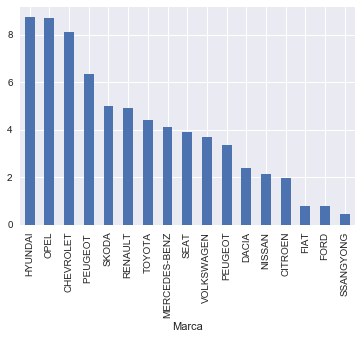
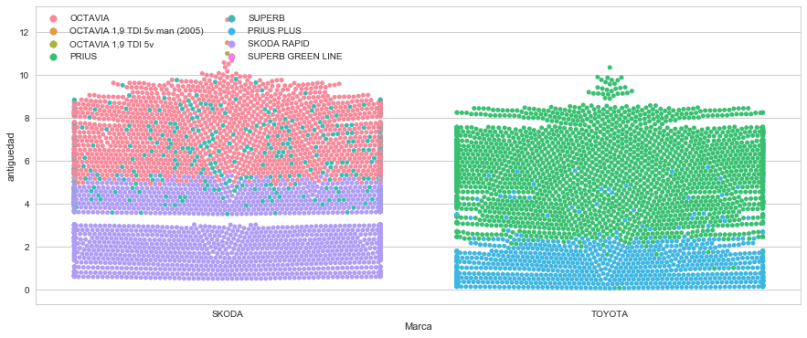
Y jugando un poco con Seaborn hemos encontrado este formato de gráficas que muestra muy claramente la contribución de cada generación de coches a esas medias :
sns.set(style="whitegrid", palette="muted") n_de_marcas=8 #filtramos a las primeras n_marcas por volumen #datos=taxis.loc[taxis['Marca'].isin(taxis_marca[:n_de_marcas].index)] lista_topn_marcas=taxis['Marca'].value_counts().index[:n_de_marcas] datos=taxis.loc[taxis['Marca'].isin(lista_topn_marcas)] # Draw a categorical scatterplot to show each observation f, ax = plt.subplots(figsize=(15, 6)) sns.swarmplot(x="Marca", y="antiguedad", ax=ax, data=datos)

Vemos que se ha dejado de vender Skodas. Hay varios huecos en Volkswagen. Fiat ha empezado a vender en los dos últimos años. Peugeot ha dejado de vender también, y Dacia ha recupeado tras algún mes sin vender.
sns.set(style="whitegrid", palette="muted") n_de_marcas=2 #filtramos a las primeras n_marcas por volumen #datos=taxis.loc[taxis['Marca'].isin(taxis_marca[:n_de_marcas].index)] lista_topn_marcas=taxis['Marca'].value_counts().index[:n_de_marcas] datos=taxis.loc[taxis['Marca'].isin(lista_topn_marcas)] # Draw a categorical scatterplot to show each observation f, ax = plt.subplots(figsize=(15, 6)) sns.swarmplot(x="Marca", y="antiguedad",hue='Modelo', ax=ax, data=datos) #lg=sns.legend_ plt.legend(ncol=2, loc='upper left')
Eso es todo!
