
Resumen
Es inherente a los algoritmos de IA sufrir un sesgo que llevado a los extremos puede reforzar la discriminación en determinados entornos, y forzar decisiones injustas. Explicaremos la base teórica, en un modelo muy simplificado, de este sesgo y añadiremos algunos ejemplos reales. Y veremos como se intentar evitar tanto desde el punto de vista legal como desde el punto de vista más técnico. Tanto los organismos responsables de la UE como muchas de las empresas del sector están lanzando recomendaciones para el diseño y operación de los algoritmos de decisión. De estas expondremos las más relevantes, que nos han de servir como guía a la hora de construirlos.
(Imagen de Somchai Chitprathak en Pixabay)
1.Introducción
En los últimos años hemos visto como se ha multiplicado el uso de los términos Machine Learning (Por su uso generalizado usaremos el término Machine Learning en vez del término en castellano aprendizaje de máquina refiriéndose a aquellas técnicas en las que se entrena un algoritmo para que estime un resultado a partir de unas variables de entrada), Inteligencia Artificial y Algoritmo. El área de influencia ocupa todos los sectores económicos de la sociedad. Más fácil que enumerarlos sería intentar encontrar un sector no influido. Las administraciones públicas y las empresas tienen un incentivo muy claro, no se trata de usar la tecnología por el hecho de usarla: esta tecnología dota de mayor eficiencia a sus procesos, bien agilizándolos, reemplazando a la persona en aquellas tareas más repetitivas o bien sustituyendo totalmente a la persona. Inherente a estos modelos de IA encontramos un efecto: el sesgo (bias en inglés). Y ese sesgo puede provocar consecuencias indeseadas o inesperadas en los proceso s controlados por esos modelos. Dependiendo de la importancia y la criticidad de esa decisión gobernada por ese algoritmo nos podríamos encontrar con situaciones potencialmente peligrosas.
Como toda revolución tecnológica también hay corrientes críticas en contra de la generalización de estas herramientas, y por supuesto el legislador no es ajeno a estas discusiones y riesgos y está trabajando intentando limitar esos efectos perniciosos.
En este documento explicaremos qué es el sesgo, de donde viene, intentaremos explicar con algún caso práctico lo peligroso que es obviarlo. Hablaremos de la legislación existe actualmente, y de las recomendaciones lanzadas desde los comités de expertos a nivel UE y España. Y finalizaremos con una reflexión sobre el estado actual con algunas recomendaciones.
2. El sesgo en los algoritmos
2.1 Un poco de teoría
Todo sistema de decisión basado en IA tiene un algoritmo basado en machine learning en los modelos más simples o deep learning (redes neuronales) en los más complejos. Para aterrizar esta idea y entender su origen e impacto vamos a introducir un modelo muy simple que nos va a servir de ejemplo explicativo.
No podemos analizar en profundidad esos modelos, pero consideramos interesante, para beneficio del lector, describir el modelo más básico posible: estimemos un valor de salida a partir de una única variable de entrada, ciñéndonos a un modelo lineal.
Simplificando mucho podemos considerar cuatro etapas en el desarrollo de un modelo:
- Recolección de observaciones
- Estandarización y Normalización de los datos
- Elección y entrenamiento del modelo de Machine Learning Óptimo
- Implementación
Por sencillez nos ceñiremos a los puntos 1 y 3. Damos por hecho que disponemos de observaciones con un formato estándar (en este caso, y de nuevo por sencillez y claridad, no normalizamos como es habitual entre ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
En la Figura 1 podemos ver la distribución de las observaciones, compuestas de un conjunto de valores 


A simple vista observamos claramente el comportamiento lineal de la función que queremos estimar. En este caso particular tenemos 100 observaciones, es decir 100 pares de datos
![(x_i,y_i) \forall i \in [0,99]](https://s0.wp.com/latex.php?latex=%28x_i%2Cy_i%29+%5Cforall+i+%5Cin+%5B0%2C99%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
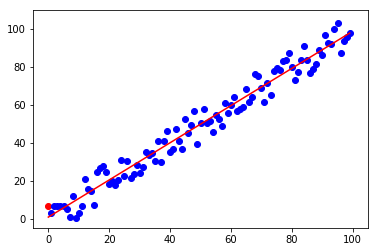
Imaginemos que estamos trabajando en un escenario en el que es muy costoso conseguir esos datos, y sólo nos podemos permitir conseguir diez observaciones, no más.
Veremos a continuación como, simplemente, la aleatoriedad en el muestreo de esos diez datos puede dar lugar a estimaciones posteriores muy diferentes, fruto de modelos ligeramente diferentes y que darían lugar decisiones diferentes.
Para ello vamos a considerar que realizamos dos procesos de extracción de datos y conseguimos dos conjuntos de entrada de diez valores cada uno. Imaginemos que nos dos procesos independientes, llevados a cabo por equipos separados, uno de ellos consigue el conjunto representado por los cuadros azules, el otro equipo consigue los datos representados por los asteriscos rojos. Podemos ver el resultado en la Figura3.

En el siguiente paso los equipos alimentaran su algoritmo, para calcular la ecuación de la curva que estime los valores en el futuro. Tras unos sencillos cálculos ambos equipo darán los resultados que definen cada curva de regresión. En la Figura3 vemos el resultado de estos cálculos.
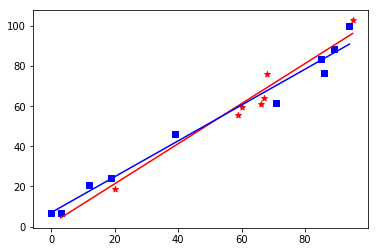
¿Qué podemos observar en esta Figura4?: qué ambas curvas tienen una pendiente diferente. ¿Y que significa eso?: que al estimar el valor 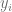

En este caso particular para 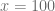
Imaginemos que el algoritmo se emplea para evaluar la idoneidad (
Hemos podido comprobar, en un ejemplo muy simple, la influencia del sesgo en un sistema de decisión.
2.2 Un ejemplo real de sesgo: el sesgo del superviviente
Veamos un ejemplo más real..
Se desarrolla en Inglaterra, en los primeros meses de su participación en la Segunda Guerra Mundial. Estaban analizando el aspecto de los aviones tras las misiones, y se pusieron a pensar como optimizar las protecciones para minimizar las bajas. Era un caso típico de compromiso: una protección máxima haría inmanejable al avión, una protección mínima lo convertiría en un aparato extremadamente vulnerable.
En la Figura4 podemos ver una simulación del aspecto que tenían estos aviones.

Se trataba de un problema con solución inmediata. Esta no era otra coas que sobre proteger aquellas zonas más castigadas. Se busco la confirmación de Abraham Walden, matemático austriaco emigrado a EEUU en los años 30. Y no confirmó la recomendación. Propuso desechar la ida presentada, y por el contrario, proteger las zonas con nulo o pocos impactos. Si estos aviones habían vuelto significaba que había soportado el daño producido por los impactos del ataque, los que no habían vuelto habían recibido impactos muy probablemente en otras zonas del fuselaje mas sensibles y que en la muestra disponible estaban bien intactas bien levemente dañadas. Ahí estaba la respuesta, esa era la zona a proteger.
De nuevo nos encontramos con un sesgo de selección. Hay que asegurarse de que la muestra que entrenará al algoritmo es una muestra representativa de la población. Y no siempre es posible, es más es extremadamente complicado asegurarse de eso.
Vemos de nuevo que el sesgo parece inherente a los modelos de IA y de Machine Learning, y que una mala elección de los datos de partida nos puede llevar a conclusiones erróneas.
2.3 El sistema de evaluación de riesgo del Sistema Penitenciario de US
El sistema COMPAS se usa en algunos estados de EEUU para ayudar en la evaluación del riesgo de encausados y convictos al solicitar libertad condicional. En el libro de David Sumpter, Outnumbered (Bloomsbury Sigma, 2019), se dedica un capítulo a analizar este procedimiento. Nos basaremos en él para ver un caso actual de como el sesgo puede impactar en la vida de las personas.
El algoritmo usa como entrada una combinación de datos empezando por el registro del recluso, la edad del primer arresto, la edad actual, nivel de educación, y las respuestas dadas a un cuestionario de una hora de duración. Estos datos, debidamente trabajados por el algoritmo, son lo que deciden si el recluso se beneficia de una libertad condicional o no.
La ONG Propublica en el articulo Julia Angwin y col. Machine Bias puso en duda la validez del modelo, achacándole un sesgo hacia las personas de color. Hizo un detallado estudio de por qué el modelo no era correcto.
David Sumpter se puso manos a la obra e intentó probar por si mismo esa afirmación.
Raza Color | Raza Blanca | |||||
|---|---|---|---|---|---|---|
| Alto Riesgo | Bajo Riesgo | Total | Alto Riesgo | Bajo Riesgo | Total | |
| Reincidente | 1.369 | 532 | 1.901 | 505 | 461 | 966 |
| No Reincidente | 805 | 990 | 1795 | 349 | 1.139 | 1.488 |
| Total | 2.174 | 1.522 | 3.696 | 854 | 1.600 | 2.454 |
En el Cuadro1 podemos ver el análisis del modelo, en el que el nivel de riesgo marca el resultado obtenido del algoritmo,Alto riesgo y Bajo riesgo y Reincidente o No reincidente marca el resultado real posterior de esa persona.
Vemos que de un total de 3.696 personas de color, 2.174 fueron etiquetadas como de alto riesgo, es decir: un 60%, mientras que sólo un 34.8% (854/2.654) de reclusos de raza blanca tenían la misma consideración. Esta aparente anomalía no significa de por si que el algoritmo tenga sesgo, puesto que, si miramos de nuevo la tabla, podemos ver que 1.901 reclusos de color, de un total de 3.615, (51.4%) fueron reincidentes, muy superior al 37.9% del otro caso.
Pero no está ahí el problema, veamos por qué.
Describamos varios conceptos relacionados con la validez o exactitud de los algoritmos de clasificación de Machine Learning:
- Positivos verdaderos, aquellos casos correctamente etiquetados como positivos equivalente a personas correctamente etiquetadas como de alto riesgo que, efectivamente, vuelven a delinquir. 1.369 en el caso de personas de color.
- Falsos positivos, aquellos casos incorrectamente etiquetados como positivos,equivalente a personas etiquetadas como de alto riesgo que no vuelven a delinquir. 349 en el caso de personas de raza blanca
- Negativos verdaderos, aquellos casos correctamente etiquetados como negativos, equivalente a personas etiquetadas como de bajo riesgo y que no vuelven a delinquir. 990 en el caso de personas de color
- Negativos falsos, equivalente a personas etiquetadas como bajo riesgo que, sin embargo, vuelven a delinquir.
- Tasa de error:
, indica una medida general de la exactitud del modelo. Específicamente indica la tasa de observaciones erróneas (
) frente a las totales.
- Sensibilidad
, es un índice que indica la probabilidad de detección. Una sensibilidad alta (muy cercana a 1) significa que
es bajo, que equivale a decir que no hemos dejado ningún positivo real detrás (
- Especificidad
Una especificidad alta significa que tiene muchos Falsos Positivo
- Precisión
, es un índice que indica el esmero con el que el algoritmo detecta los TP. Una
alta significa que hay pocos
, que un alto numero de positivos son realmente $TP$. Una alta Precisión viene a indicar que el modelo es bueno identificando como positivos los que realmente son positivos.
| Raza de color | Raza blanca | |
|---|---|---|
| TP | 1.369 | 505 |
| FP | 805 | 349 |
| TN | 990 | 1.139 |
| FN | 532 | 461 |
| Tasa de error | 36,2% | 33% |
| Sensibilidad | 72% | 52,3% |
| Precision | 63% | 59,1% |
Comparando los valores correspondientes a raza de color y raza blanca podemos observar que las tasa de error están en el mismo rango de exactitud. Si miramos el valor de Precisión vemos que hay aproximadamente un 4% de diferencia, de nuevo podemos asumir que la precisión en ambos casos es similar. Sin embargo en la línea de Sensibilidad encontramos una diferencia que no podemos pasar por alto. ¿Qué significan esos diferentes valores?: en el caso de raza negra el modelo tiene significativamente más sensibilidad, que significa que hay menos Falsos Negativos. Visto de otra manera significa que en el caso de Raza Blanca hay más Falsos negativos, es decir : si eres blanco y reincidente tienes más posibilidades de que el modelo «se confunda» y te etiquete (erróneamente) como de bajo riesgo. El modelo identifica mejor a un positivo de raza negra que a un positivo de raza blanca.
De nuevo podemos ver como un algoritmo que va a decidir si vas a vivir en libertad o no en los próximos meses tiene un sesgo nada despreciable.
Es un modelo correcto en cuanto a tasa de error general, o en cuanto a precisión (identifica con igual éxito a una gran parte de positivos) independientemente de si la raza es blanca o es negra : obtiene la misma calificación de Falsos positivos respecto al total de positivos, sin embargo, como individuo, si formas parte del grupo de raza negra tienes menos posibilidades de que el algoritmo se confunda a tu favor, tienes menos posibilidades de ser un Falso Negativo.
Podemos discutir si eso es justo o no, pero en (Sam Corbett-Davies, Emma Pierson y Sharad Goel: Algorithmic decision making and the cost of fairness) se encargaron de demostrar que la tasa de error y la precisión similares hacía que el algoritmo se considerara bien construido pues la realidad es que, si un grupo es más reincidente que otro, entonces es imposible tener una sensibilidad igual, dicho de otro modo, en el grupo menos reincidente tendrás mas posibilidades de ser Falso negativo (The University of Edinburgh. (The Bias-Variance Tradeoff))
De nuevo vemos como el sesgo en general sea imposible de evitar.
2.4 Conclusión sobre el sesgo
Hemos visto una descripción teórica del sesgo, y hemos descrito un par de casos reales en los que puede impactar en aspectos muy sensibles (la vida de un piloto, y la libertad, y quizá la vida, de un recluso) en dos escenarios muy diferentes. Veamos ahora como se aborda este problema desde el punto de vista de la legislación, y nos extenderemos un poco más para entender que recomendaciones hay que seguir para evitar que el sesgo provoque situaciones totalmente indeseables.
3. Legislación sobre el sesgo del algoritmo
Veamos como el legislador ha considerado el ataque al problema del sesgo en los algoritmos. Exponemos a continuación los artículos relacionados.
En el GDPR (General Data Protection Rule ó Reglamento General de Protección de Datos) encontramos el artículo 22:
Artículo 22: Decisiones individuales automatizadas, incluida la elaboración de perfiles
Todo interesado tendrá derecho a no ser objeto de una decisión basada únicamente en el tratamiento automatizado, incluida la elaboración de perfiles, que produzca efectos jurídicos en él o le afecte significativamente de modo similar
El apartado 1 no se aplicará si la decisión:
es necesaria para la celebración o la ejecución de un contrato entre el interesado y un responsable del tratamiento;
está autorizada por el Derecho de la Unión o de los Estados miembros que se aplique al responsable del tratamiento y que establezca asimismo medidas adecuadas para salvaguardar los derechos y libertades y los intereses legítimos del interesado, o
se basa en el consentimiento explícito del interesado.
En los casos a que se refiere el apartado 2, letras a) y c), el responsable del tratamiento adoptará las medidas adecuadas para salvaguardar los derechos y libertades y los intereses legítimos del interesado, como mínimo el derecho a obtener intervención humana por parte del responsable, a expresar su punto de vista y a impugnar la decisión.
Las decisiones a que se refiere el apartado 2 no se basarán en las categorías especiales de datos personales contempladas en el artículo 9, apartado 1, salvo que se aplique el artículo 9, apartado 2, letra a) o g), y se hayan tomado medidas adecuadas para salvaguardar los derechos y libertades y los intereses legítimos del interesado..
En el caso de la Ley de Protección de Datos Personales el artículo 11 es el correspondiente a perfilados y decisiones automáticas:
Artículo 11. Transparencia e información al afectado.
- Cuando los datos personales sean obtenidos del afectado el responsable del tratamiento podrá dar cumplimiento al deber de información establecido en el artículo 13 del Reglamento (UE) 2016/679 facilitando al afectado la información básica a la que se refiere el apartado siguiente e indicándole una dirección electrónica u otro medio que permita acceder de forma sencilla e inmediata a la restante información.
- La información básica a la que se refiere el apartado anterior deberá contener, al menos:
- La identidad del responsable del tratamiento y de su representante, en su caso.
- La finalidad del tratamiento.
- La posibilidad de ejercer los derechos establecidos en los artículos 15 a 22 del Reglamento (UE) 2016/679.
- Si los datos obtenidos del afectado fueran a ser tratados para la elaboración de perfiles, la información básica comprenderá asimismo esta circunstancia. En este caso, el afectado deberá ser informado de su derecho a oponerse a la adopción de decisiones individuales automatizadas que produzcan efectos jurídicos sobre él o le afecten significativamente de modo similar, cuando concurra este derecho de acuerdo con lo previsto en el artículo 22 del Reglamento (UE) 2016/679
- Cuando los datos personales no hubieran sido obtenidos del afectado, el responsable podrá dar cumplimiento al deber de información establecido en el artículo 14 del Reglamento (UE) 2016/679 facilitando a aquel la información básica señalada en el apartado anterior, indicándole una dirección electrónica u otro medio que permita acceder de forma sencilla e inmediata a la restante información. En estos supuestos, la información básica incluirá también:
- Las categorías de datos objeto de tratamiento.
- Las fuentes de las que procedieran los datos.
4. ¿Cómo evitamos el riesgo del sesgo?
4.1 Una visión general
Podemos comprobar como el legislador es extremadamente sensible a los problemas relacionados con el sesgo y como pretende evitar los efectos indeseados que hemos visto en el Capítulo II.
Implementar modelos que tomen de manera automática decisiones que puedan afectar de manera notable a las condiciones de vida de los ciudadanos, una vez que sabemos que esos modelos sufren de sesgos de forma irresoluble, no parece una tarea muy responsable.
Pero por otra parte, tal como dice Ricard Martínez:
Sin embargo, desde el Derecho debemos aproximarnos al fenómeno de un modo más matizado. Si caemos en la trampa de demonizar la tecnología desde una óptica puramente preventiva corremos el riesgo de paralizar el avance del conocimiento y de las ventajas que pueda proporcionara nuestra sociedad.
Tomás de la Quadra-Salcedo y Jose Luis Piñar Mañas Sociedad Digital y Derecho, 2018
Es extremadamente importante buscar ese equilibrio en el que no se entorpezca la implantación de técnicas de IA que optimicen procesos pero siempre salvaguardando los derechos de los ciudadanos. Este mismo autor cita, sin pretender ser una lista exhaustiva, una serie de escenarios en los que esta IA está jugando un papel estratégico:
- Marketing y profiling
- Medicina
- Confiabilidad del cliente en entornos bancarios y aseguradores
- Analítica de Recursos humanos
- Asistentes virtuales y negocios que requieren de análisis semántico y lingüístico
Se añade a este problema la pujanza de estas tecnologías desde geografías en las que, quizá, la defensa de la privacidad no está tan desarrollada y asumida como en Europa.
4.2. Recomendaciones desde la UE
El AI HLEG (High-Level ExpertGroup on Artificial Intelligence) , desde la UE, ha estudiado profundamente esta problemática y ha publicado el documento : Ethics guidelines for trustworthy en el que hace una serie de recomendaciones éticas a los desarrolladores y arquitectos de conseguir que la AI sea digna de confianza.
4.2.1. Pilares de una AI confiable
Para empezar dicta tres normas generales que debe seguir cualquier aplicación de AI:
- Ha de cumplir la ley. Los modelos de AI, en general, no se desarrollan e implementan en entornos cerrados de laboratorio con nula interacción con las personas. Se desarrollan para optimizar procesos que impactaran con ellas. Y justo por eso el proceso ha de seguir una serie de reglas y fuentes legales de obligado cumplimiento. Podríamos enumerar, de forma no exhaustiva, las siguientes:
- Los derechos fundamentales fundacionales de la Unión Europea
- General Data Protection Rule
- Directiva de responsabilidad de productos y servicios
- Ley de Consumo
- Directivas de Seguridad e Higiene en el trabajo
- La declaración de derechos humanos de la ONU
- Ha de respetar y cumplir con los valores y principios éticos:
- Ha de ser robusta desde un punto de vista técnico, de tal manera que se ciña en toda circunstancia a los parámetros y principios sobre la que se diseño y construyó.
A los efectos de desarrollar la aplicación práctica de estos tres pilares o normas generales nos basaremos en los dos artículos de la GDPR de la sección III, y la interpretación que de los mismos hace el WP29 (Este Working Party se estableció como ente consultor de la UE en materia de Protección de Datos y Privacidad. Sus tareas se describen en el art 30 de la Directiva 95/46/EC para el Principio de Cumplimiento de la Ley y en el documento referenciado en la introducción de este capítulo,Ethics guidelines for trustworth, para el Principio Ético y el Principio de Robustez.
4.2.2. Efecto del artículo 22 GDPR en los algoritmos de decisión
Vamos a analizar a continuación los escenarios cubiertos por el articulo 22 de la GDPR en cuanto a sistemas automáticos de decisión. Nos basamos en las ideas propuestas en el documento Art 29 Working PArty, Guidelines on Automated individual decision-making and Profiling for the purposes of Regulation 2016/679. 2017. Como norma general el artículo 22(1) nos advierte de la prohibición de que haya algoritmos de decisión automáticos , incluidos perfiles, que concluyan en un efecto legal o equivalente. A continuación, artículo 22(2) nos indica que hay una serie de excepciones para finalizar asegurando unas salvaguardas de los derechos de la persona.
La prohibición del 22(1) se refiere a decisiones tomadas exclusivamente con algoritmos, es decir : no hay intervención humana en el proceso. Aqui hay que prevenir de que esta prohibición no se puede evitar forzando una intervención humana con el solo objetivo de simularla. Como ejemplo: una proceso en el que una persona simplemente aplica lo que dice el algoritmo estaría afectado por esta limitación.
Para que una intervención humana se catalogue como tal se ha de asegurar que se fuerza a la persona a entender la situación y tomar una decisión basada en ella, y no sólo un mero gesto para que el flujo del proceso continúe. Un simple «Aceptar» para pasar al siguiente paso en absoluto se puede considerar como intervención humana.
El artículo 22 habla de «Efectos Legales«. Es conveniente que veamos a que se refieren estos ya que no están definidos en el documento.
Entendemos que un \emph{efecto legal} lleva implícito un reconocimiento de que tiene un impacto en los derechos de una persona, como podría ser la libertad de asociación, votar en unas elecciones, o poner en marcha una acción legal como una demanda. Afecta también a aquello que impacta en la situación de una persona o en la posición legal en un determinado contrato. Podemos ver como ejemplos de esto:
- Autorizar o denegar a una persona un determinado beneficio legal al quetiene derecho
- Denegación de paso de fronteras.
- Ser sujeto de un incremento de vigilancia o de medidas de seguridad por parte de los organismos competentes de seguridad.
- Desconexión automática de un servicio de telecomunicaciones por causa de incumplimiento de contrato por no pagar a tiempo una factura antes de salir de vacaciones, por que el sistema identificó un potencial fraude.
Por otra parte, incluso si no afecta a derechos legales, el modelo podría verse influido por el artículo 22 si el efecto es significativo. El documento de referencia incluye algunos ejemplos tales como:
- Consumo a crédito.
- Obtención de una hipoteca para la compra de la primera vivienda.
- Alquiler de un coche.
Como reflexión rápida podemos considerar que no es extremadamente grave verse impactado en una de las situaciones anteriores, pero si entenderemos como muy grave que las decisiones estándares para un determinado segmento de población estén sesgadas y tenga como consecuencia un impacto grave en su vida.
Vemos también que existen una serie de excepciones a esa prohibición de implantar sistemas de decisión automática sin intervención humana. Estas excepciones están resumidas en tres tipos:
- Para la correcta ejecución de un contrato. En determinadas ocasiones el proveedor del servicio puede considerar que un sistema de decisión automático es necesario para el desarrollo efectivo del contrato.
Por ejemplo en casos en los que se incremente la rigurosidad del proceso de la decisión disminuyendo la intervención humana, o eliminando el abuso de poder. O bien se reduzca el riesgo de impago de los bienes o servicios entregados bajo el contrato por parte del cliente (aquí se incluiría los credit scoring). O simplemente el modelo ayuda a ejecutar procesos de decisión de una manera más ágil y efectiva. En determinados entornos puede darse el caso de que la intervención humana sea simplemente imposible (por el volumen de datos a gestionar, o por la velocidad intrínseca al proceso por ejemplo). Sin embargo el WP22 considera que estas situaciones por si mismas no justifican que sea absolutamente necesarias para la correcta ejecución del contrato. La parte interesada del contrato debe justificar que no se puede utilizar un modelo menos intrusivo, y que la decisión automática es la única manera de llegar al correcto cumplimiento del contrato. - Está autorizada por la Unión Europea o alguno de sus Estados.
Bajo esta excepción se autorizarían Modelos de decisión automática cuyo objetivo fuera monitorizar situaciones de fraudes potenciales, específicamente riesgos de lavado de dinero, evasión de impuestos etc.. - El sujeto del dato ha consentido el uso de manera explícita.
Se requeriría un consentimiento claro en el que se le informe debidamente al sujeto del dato el objetivo del tratamiento de este. No ha de dejar ninguna duda de qué proceso se va a implementar.
4.2.3. Principios éticos
- Principio autonomía de la persona :
- En el sentido de que los derechos fundamentales de libertad y autonomía, sobre los que se erige la UE, han de ser respetados en las interacciones de las personas con los sistemas de AI. El objetivo de estos ha de ser el aumento de las capacidades cognitivas, sociales y culturales de las personas, y en ningún caso se permitirá que la AI subordine, manipule u obligue a la persona. En resumen se ha de asegurar la ascendencia del hombre sobre la máquina.
- Principio de prevención del daño
- El sistema de AI no ha de afectar negativamente a la persona, ha de funcionar para asegurar su integridad física y mental. Para ello será técnicamente robusto y no accesible a usos malintencionados. En particular se ha de asegurar que no participa en modelos con asimetría de control, poder o disponibilidad de la información. Como ejemplos de este caso encontraríamos las relaciones laborales jefe-subordinado, negocios-consumidores, o estado-ciudadano.
- Principio de justicia
- En el sentido de que se permita una distribución equitativa de los beneficios y los costes, y (relacionado con el objetivo de este trabajo) no sea víctima de sesgos injustos, o de discriminación y estigmatización. Y que, por supuesto, se asegure acceso con igualdad de condiciones a la educación, servicios y tecnología. Como condición necesaria para que estos requerimientos sean alcanzables se habrá de cumplir que la entidad responsable de la decisión sea identificable y que el algoritmo sea explicable.
- Principio de explicabilidad.
- Ha de ser posible explicar como funciona el algoritmo.Este principio es pilar central para asegurar la confianza en los modelos de AI. El proceso del modelo ha de ser transparente, las capacidades comunicadas de manera abierta y las decisiones debidamente comunicadas a las personas afectadas por ellas.
Y siguiendo el desarrollo del marco conceptual, para que se cumplan estos principios nos ofrece siete requerimientos básicos que se han de atender. Los vemos en la siguiente sección.
4.2.4. Requerimientos para asegurar el cumplimiento de los principios éticos
- Guía humana y supervisión: Los sistemas de IA deben soportar la autonomía y la capacidad de decisión de la persona, han de comportarse a favor del desarrollo de una sociedad más democrática. El respeto a los derechos fundamentales, la prevalencia de la voluntad de la persona a la hora de utilizar los modelos de AI como ayuda a la toma de decisiones (es decir : la voluntad última es la de la persona) y el aseguramiento de que hay una supervisión humano por encima del proceso son aspectos cruciales a tener en cuenta. Aquí encontraríamos modelos tales como HITL: Human in the Loop, HOTL: Human on the Loop y HIC: Human in command}. Vemos la relación directa de este requerimiento con el artículo 22.1 de GDPR.
- Robustez técnica y seguridad: Aspecto también crucial para asegurar una AI confiable. Este requerimiento está íntimamente relacionado con el principio de prevención del daño. Los modelos de AI se han de implementar manteniendo ese principio como prioritario, asegurando que su funcionamiento se ciñe a los criterios de diseño y se minimizan todo lo posible los comportamientos inesperados. A añadir a los criterios de diseño tendríamos la aplicación de técnicas de ciberseguridad, planes de marcha atrás en caso de aparición de problemas inesperados, criterios de grados mínimos aceptables de exactitud en las predicciones y replicabilidad de datos (los resultados de los modelos son iguales cuando las entradas son iguales). Estos aspectos son los que se han de tener en cuenta en las etapas iniciales del diseño del modelo.
- Privacidad y gobernanza del dato: La privacidad está también unida al principio de prevención del daño. En todo el ciclo de vida del modelo se asegurará que el dato, tanto los de entrada como la salida del modelo, está correctamente salvaguardado, impidiéndose cualquier uso que pueda devenir en una discriminación de cualquier tipo a la persona.Tan importante como la privacidad es el aseguramiento de la integridad del lado. Recordemos los ejemplos reales de sesgos: entrenar con datos que no representan fielmente al universo de entrada dará lugar a modelos sesgados que ofrecerán resultados que no cumplen ninguno de los principios éticos que estamos viendo.
- Transparencia: Este requerimiento está relacionado con el \emph{principio de explicabilidad}, y su objetivo es asegurar la transparencia de los elementos del modelo: los datos, el sistema y el modelo de negocio. En términos prácticos se nos requiere que el modelo esté debidamente documentado, tanto desde el punto de vista de generación y captura de los datos hasta su normalización como del propio modelo en sí. Implica también que el modelo sea explicable, luego entendido y trazable. Añadimos por último el matiz de la comunicación. Actualmente estamos viendo la proliferación de chatbots (sistema de interacción hombre-máquina por medio de síntesis de voz o bien por medio escrito. Se está utilizando como medio de comunicación inmediato en webs o en servicios de mensajería. El usuario solicitará sus peticiones en lenguaje natural) como medio alternativo de comunicación en contact-centers, en estos casos ha de estar perfectamente indicado que la persona está interaccionando con una máquina y no con una persona.
- Diversidad, no discriminación y honestidad: Este requerimiento está relacionado con el principio de justicia. Y nos encontramos de nuevo aquí con el problema del sesgo. Por una lado, y ya nos hemos referido a ello anteriormente, aseguraremos que identificamos en todo lo posible el sesgo en la selección de los datos con los que entrenaremos al modelo, evitando con ello prejuicios y discriminaciones indeseadas, y por otro lado evitaremos sesgos en el propio diseño del algoritmo. Podremos atender este punto añadiendo un proceso de supervisión y control en todo el diseño del algoritmo. Como punto adicional se refiere a que una diversidad del propio equipo humano de desarrollo ayudaría a que se cumpliera con ese requerimiento. Asegurar que el sistema es accesible de manera equivalente por todas las personas independientemente de su edad, raza, género, o nivel de capacidad es también un principio de diseño requerido para asegurar la no discriminación.
- Bienestar social y cuidado del medio ambiente En línea con el principio de prevención del daño debemos considerar que este no aplica sólo a las personas. Hemos de incluir como sujetos del mismo a la sociedad en su más amplio sentido del concepto, a otros seres vivos y al medio ambiente. De alguna manera estaríamos asegurando que este modelo es respetuoso con generaciones venideras, no solo con las actuales. Dentro de este capítulo incluiríamos el minimizar el gasto de energía (especialmente importante en el proceso de entrenamiento). Ya hemos comentado el impacto social de la AI, el riesgo cierto de que deterioren las capacidades de las personas exige extremar el esfuerzo a la hora de su diseño, y a la hora de operarlo.
- Responsabilidad: Por último tenemos el requerimiento de responsabilidad, relacionado con el principio de justicia. No solo se refiere a que el sistema sea auditable (que ya lo hemos mencionado anteriormente) sino que se establezcan una serie de medidas para asegurar que los usos incorrectos sean reportados, que se dote de medios para comunicar e informar de denuncias de incorrecciones del modelo, que aseguren el anonimato y seguridad del llamante.
Hasta aquí hemos visto los requerimientos que se le piden a un modelo de AI para poder cumplir con los principios éticos del punto2. El documento High-Level Expert Group. Ethics guidelines for trustworthy AI. 2019. recomienda una serie de métodos técnicos y no técnicos para una correcta implementación de estos requerimientos. De entre ellos es importante resaltar el rule-of-law-by-design. Diseñar modelos de AI con un efecto mínimo del sesgo exige que el cumplimiento de la ley sea un requisito omnipresente e ineludible en todos las etapas del diseño.
4.3. Otras recomendaciones
Adicionalmente a las recomendaciones hechas desde el equipo AI HLEG he encontrado un gran número de ellas desde universidades y empresas. He seleccionado una fuente en especial Henry Hinnefeld. ((Reducing bias and ensuring fairness in data science)), por la claridad en la exposición y por el prestigio del fundador de la empresa: Dan Wegner : Civis civisanalytics.com, quien fue Data Analytics Officer del Presidente Obama en la campaña electoral de 2012 en la que fue reelegido como Presidente de los EEUU.
En el trabajo de la referencia se hacen tres recomendaciones para tratar de manera efectiva con el sesgo en los algoritmos :
- Reflexiona sobre la «realidad sobre el terreno» (Realidad sobre el terreno es la mejor traducción que he encontrado del término ground-truth). Hay que asegurarse de que nosotros mismos no estamos sesgados de antemano a la hora de diseñar el modelo, y que resultados o experiencias pasadas no nos están inclinando a forzar resultados de una u otra manera
- Reflexiona sobre el proceso que generó los datos con los que estás trabajando. Entiende el proceso de extracción, ¿está cogiendo los datos de partida con unos valores por defecto en especial?, ¿es un conjunto significativo de datos?, ¿es una muestra representativa?. Si no lo haces conseguiremos algoritmos con resultados pobres en el caso mejor, y ayudaremos a perpetuar el sesgo (con las consecuencias negativas que conocemos) en el caso peor.
- Si el modelo afecta a las personas, mantén a las personas en el proceso. Es la más importante de las tres, y que quizá resume las recomendaciones vistas a lo largo del trabajo. Tenemos una tendencia natural, que he comprobado en muchas discusiones con compañeros interesados en la AI, a creer que, por el hecho de que esté basada en computación dirigida por un software bien construido sobre reglas matemáticas claras y objetivas,los modelos de AI son de manera natural justos. Y estamos más que lejos de esa situación. La realidad es que construir modelos basados en datos sesgados producirán indefectiblemente resultados sesgados. Depende de nosotros el que el modelo sea justo. Y, desgraciadamente, no tenemos un procedimiento universal para asegurar que el modelo lo sea siempre. Dependerá de la tarea en particular y requerirá en todo caso de la intervención del ser humano.
5. Conclusión
A lo largo del trabajo he tratado de explicar el problema del sesgo en los algoritmos y modelos de AI. Como es parte sustancial del proceso matemático de construcción del modelo, y como se puede empeorar simplemente eligiendo mal los datos de entradas. Los problemas que puede acarrear son potencialmente muy graves, pueden provocar la limitación de derechos en personas y puede afectar a decisiones injustas sobre determinados conjuntos de la población. El legislador es plenamente consciente de estos riesgos, al igual que es consciente de la tremenda contribución de la AI al desarrollo cultural, económico y social de la sociedad actual. Por ello ha incluido en la GDPR artículos para tener ese riesgo bajo control y ha tomado decisiones para permitir que los expertos recomienden como han de desarrollarse esos modelos. El sector privado no es tampoco ajeno, y hemos visto algunas recomendaciones al respecto.
Es crítico seguir trabajando en esta línea, y todo el sector de la AI ha de ser consciente de que un mal uso de ella puede provocar el menoscabo de derechos fundamentales de la persona. En el dominio de la AI el hacer un software efectivo, con tiempo de ejecución mínimo, que sea robusto ante fallos, y que sea amigable desde el punto de vista de usuario no es suficiente, tenemos que conseguir entre todos los participantes que ese modelo, y el software que lo soporta, este construido sobre un principio irrenunciable de control del sesgo.
