
Un recordatorio: el teorema de Bayes
Licencia : https://creativecommons.org/licenses/by-nc-sa/4.0/
Empecemos con el uso «estandar» del Teorema. Lo vamos a aplicar a un problema clásico, el de las bolsas con bolas de colores:
Sean dos bolsas indistinguibles, la primera, llamémosla bolsa 1, tiene 4 bolas verdas y una bola roja, la segunda, llamémosla bolsa 2, tiene 2 bolas verdes y tres bolas rojas. Se elije al azar una de las bolsas y obtenemos una bola verde, ¿qué probabilidad hay de que esta venga de la bolsa 1?
Recordamos la formulación del teorema:

La aplicación nos resultaba sencilla, teniamos que saber cual era la condición (por aquello de probabilidad condicional!),
En nuestro caso:



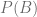
Aplicándolo a nuestro problema, A representa el suceso bolsa de la que se ha sacado la bola {1,2}, y B representa el color de la bola : {verde, roja}.
Con lo que nos queda :

La 



Luego

Hemos calculado la probabilidad solicitada basándonos en el Teorema de Bayes pensando en modo «condición». Pero podemos retorcer un pelín el problema: podemos pensar en que, antes del experimento, P(A) es la posibilidad de que sea una bolsa a priori, sin informacion previa. Es nuestra distribución ‘a prior’, y 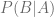
a posterior, sabiendo de que bolsa viene: si sabemos que la bolsa elegida es 1, que posibilidad tenemos de que sea verde la bola elegida?.
Veámoslo de la siguiente manera:

Tal como comentaba en el parrafo anterior : corregimos nuestro creencia a priori de que la distribución es equitativa al 50% con la información que hemos recibido: la bola es verde. Aplicamos fórmula y tendremos que la nuEva probabilidad a posteriori es de 2/3 y no 1/2 como pensabamos antes de disponer de la información. Es a esto a lo que me refiero con forma de pensar Bayesiana. Tenemos nuestra creencia, visualizamos una función de distribución de probabilidad previa,a priori, observamos datos y actualizamos esa función de distribución.
Veámoslo con otro ejemplo y con un poco de Python
¿está esta moneda balanceada?
Este ejemplo y el código está basado en el notebook del profesor Allen B Downey, en el que se estudia el balanceo o desbalanceo de una moneda conforme vamos obteniendo resultados. Y como podemos inferir finalmente si la moneda está balanceada o no.
Para aplicarlo a nuestra discusión vamos a realizar el siguiente ejercicio.
Disponemos de una moneda de la que no tenemos ninguna información a priori sobre su ajuste. La tiramos al aire en multiples ocasiones y vamos apuntando los resultados. ¿Cómo inferimos información sobre su ajuste tras ir viendo las evidencias de estos resultados?
Ahora hablaremos de pmf, o función de probabilidad (Probability Mass Function, al ser variable discreta), que se define tal que 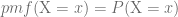


En este ejercicio
Vamos a ello:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Creamos una función para generar la pmf :
def crear_pmf(x, p):
"""Devolvemos una pmf de la variable aleatoria X
x: todos los valores posibles del balanceo
ps: probabilidades de la variable aleatoria
returns: Pandas Series
"""
pmf = pd.Series(p, index=x)
pmf /= pmf.sum()
return pmf
..y una función para actualizarla conforme vamos obteniendo datos:
def actualizar_pmf(pmf_original, data):
"""Actualizacion de la pmf de la variable.
pmf: pmf a actualizar
data: evidencias. Pasadas como un set de número de caras,y cruces,
al realizar el experimento caras+cruces veces,
"""
caras, cruces = data
x = pmf_original.index
pmf = pmf_original
#Que evidencia usamos si obtenemos una cara?:
#pues decidimos usar una distribución en la que pmf(X=0)=0
#(es imposible que salga cara si la probabilidad de que salga es cero)
#, y con probabilidad creciente hasta llegar a 100%.
#La probabilidad de cruz será 1-probabilidad_cara
evidencias_cara = x / 100
evidencias_cruz = 1 - evidencias_cara
for i in range(caras):
pmf *= evidencias_cara
for i in range(cruces):
pmf *= evidencias_cruz
pmf /= pmf.sum()
return pmf
Ya hemos construido las dos funciones que necesitamos, una para crear el pmf y otra para actualizarlo.
Creamos ahora los datos: x que representa la variable aleatoria, con valores entre 0% y 100%, y la probabilidad de cada valor..
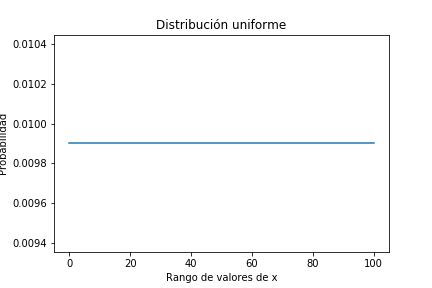
Para empezar apliquemos la información de la que disponemos de esa moneda: textualmente el ejercicio dice : «Disponemos de una moneda de la que no tenemos ninguna información a priori sobre su ajuste», luego no sabemos si es 0 (todas cruces), 100% (todas caras) o cualquier valor entre ellos. Hagamos pues una distribución uniforme entre 0% y 100% (ojo, son 101 datos, incluyendo 0 y 100):
xs = np.arange(101)
prior = 1/101
pmf_prior = crear_pmf(xs, prior)
pmf_prior.plot()
plt.xlabel('Rango de valores de x')
plt.ylabel('Probabilidad')
plt.title('Distribución uniforme');
plt.savefig('fig1')
Y procedemos a actualizar
data = 100, 100
pmf_posterior=actualizar_pmf(pmf_prior, data)
Veamos el resultado obtenido
pmf_posterior.plot()
plt.xlabel('Rango de valores de x')
plt.ylabel('Probabilidad')
plt.title('Distribución a posteriori');
plt.savefig('fig2')
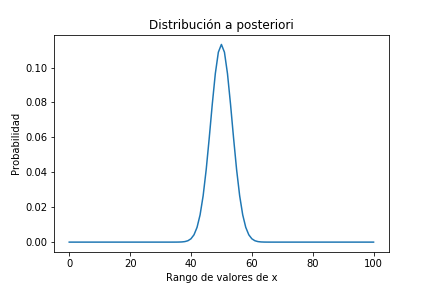
pmf_posterior.mean()
0.009900990099009901
pmf_posterior.idxmax()
50
Vemos que con esos datos (100 caras y 100 cruces) el resultado es una campana con valor máximo en 50%. Ojo, que la probabilidad de que realmente obtengamos 100 y 100 es de menos del 1%!
Vamos a tensar el modelo con creencias «sesgadas»
Hagamos ahora el siguiente experimento.
Utilicemos como prior una distribución totalmente sesgada a un extremo, con probabilidades altas en el entorno del 10% y muy bajas en el entorno del 90%. En el resto de valores tiene un valor muy bajo, pero no es nulo.
xs = np.arange(101)
p = [1 for i in xs]
for i in range(1,20,1):
p[i]=100
pmf_prior=crear_pmf(xs,p)
pmf_prior.plot()
plt.xlabel('Rango de valores de x')
plt.ylabel('Probabilidad')
plt.title('Distribución sesgada hacia el cero');
plt.savefig('fig3')
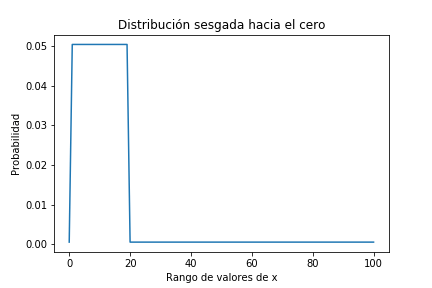
pmf_prior[10]
0.050454086781029264
pmf_prior[90]
0.0005045408678102926
Efectivamente vemos que la posibilidad de quela probabilidad de la moneda sea 10% es 100 veces más elevada de que sea 90%.
Actualicemosla con los mismos valores que en el anterior experimento:
data = 100, 100
pmf_posterior=actualizar_pmf(pmf_prior, data)
pmf_posterior.plot()
plt.xlabel('Rango de valores de x')
plt.ylabel('Probabilidad')
plt.title('Distribución a posteriori');
plt.savefig('fig4')
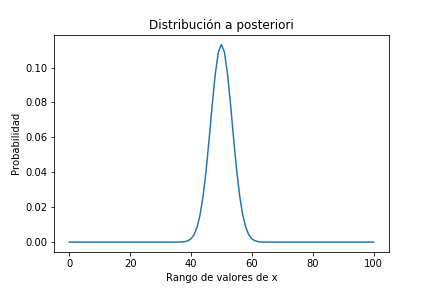
pmf_posterior.mean()
0.009900990099009901
Qué vemos en esta figura?..es la misma que en el experimento anterior, significa que aunque nuestra creencia previa estuviera sesgada el resultado final es equivalente.
Sesgemos más nuestra creencia previa
En esta ocasión nuestra creencia a priori estará muy sesgada hacia un extremo pero con valores nulos en el otro. Es decir creemos que está en un extremo y estamos absolutamente seguros de que NO lo está en el otro:
xs = np.arange(101)
#por defecto damos valor zero en todo el rango
p = [0 for i in xs]
for i in range(80,101,1):
p[i]=100
pmf_prior=crear_pmf(xs,p)
pmf_prior.plot()
plt.xlabel('Rango de valores de x')
plt.ylabel('Probabilidad')
plt.title('Distribución sesgada hacia el cero');
plt.savefig('fig5')
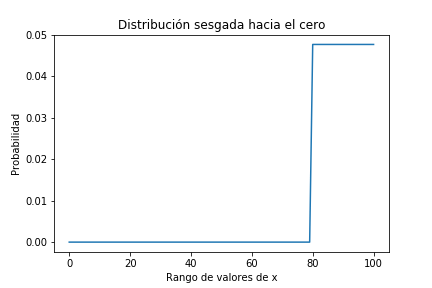
pmf_prior[90]
0.047619047619047616
pmf_prior[5]
0.0
Y actualicemoslo con 990 cara y 1010 cruces
data = 99, 101
pmf_posterior = actualizar_pmf(pmf_prior, data)
pmf_posterior.plot()
plt.xlabel('Rango de valores de x')
plt.ylabel('Probabilidad')
plt.title('Distribución a posteriori');
plt.savefig('fig6')
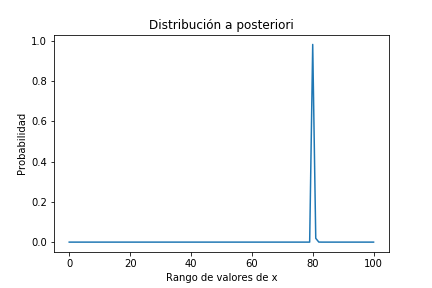
pmf_posterior.sum()
1.0000000000000002
¿Qué ha ocurrido?: que al tener una creencia previa equivalente a un zero absoluto en que el valor del balance de la moneda sea 50% (nuestra pmf_prior[50]=0) por muchas evidencias posteriores que nos encontremos el resultado será siempre una pmf[50]=0, aunque los datos insistan en que el valor está en ese entorno.
El modelo Bayesiano nos da un consejo: no seas radical en tus pensamientos, corres el riesgo de que por muchas evidencias que veas de que estás equivocado no puedas cambiar ese prejuicio!
