
Vamos a preparar un script que nos permita evaluar las variaciones que hay en los cambios de moneda, y nos de una idea de que riesgos estamos corriendo cuando fijamos los cambios. Las series históricas las sacamos de la libreria https://pypi.org/project/investpy/ (construída por Álvaro Bartolomé del Canto @alvarob96 at GitHub) que obtiene los datos de la web de información financiera http://www.investing.com
import investpy
import pandas as pd
from datetime import datetime,timedelta
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
from matplotlib import cm
import numpy as np
import seaborn as sns
%matplotlib inline
import matplotlib.dates as mdates
import matplotlib.ticker as ticker
pd.set_option('display.max_rows', 20)
Preparación de los datos
Creamos unas variables auxiliares que necesitaremos durante este trabajo, y que nos facilitan las pruebas y debugging:
hoy=datetime.strftime(datetime.today(),'%d/%m/%Y')
hoy_index=datetime.strftime(datetime.today(),'%Y/%m/%d')
desde_2016='01/01/2016'
desde_2018='01/01/2018'
verano_2019='01/07/2019'
def hoy_menos(n_days):
''' devuelve un datetime del day_n ésimo anterior a hoy'''
return datetime.today()-timedelta(days=n_days)
Bajamos los datos del repositorio.
df = investpy.get_currency_cross_historical_data(currency_cross='EUR/USD',
from_date=verano_2019,
to_date=hoy)
df.head()
| Open | High | Low | Close | Currency | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-07-01 | 1.1375 | 1.1375 | 1.1280 | 1.1285 | USD |
| 2019-07-02 | 1.1286 | 1.1321 | 1.1275 | 1.1285 | USD |
| 2019-07-03 | 1.1284 | 1.1311 | 1.1268 | 1.1278 | USD |
| 2019-07-04 | 1.1277 | 1.1296 | 1.1272 | 1.1285 | USD |
| 2019-07-05 | 1.1285 | 1.1289 | 1.1207 | 1.1226 | USD |
df.index
DatetimeIndex(['2019-07-01', '2019-07-02', '2019-07-03', '2019-07-04',
'2019-07-05', '2019-07-08', '2019-07-09', '2019-07-10',
'2019-07-11', '2019-07-12',
...
'2020-07-06', '2020-07-07', '2020-07-08', '2020-07-09',
'2020-07-10', '2020-07-13', '2020-07-14', '2020-07-15',
'2020-07-16', '2020-07-17'],
dtype='datetime64[ns]', name='Date', length=275, freq=None)
El respositorio nos da los valores diarios con las aperturas, cierres, máximos y mínimos.
Veamos una gráfico de ejemplo con el valor de apertura:
df['Open'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fc532e80890>
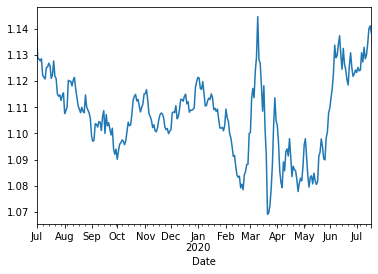
Vamos a añadir un par de variables: averagecomo media movil de una ventana de 90 días y stdque indicaría la desviación estandar de los cambios de esos noventa dias
ventana = 90
df['average'] = df.loc[:,'Open'].rolling(window=ventana).mean()
df['std'] = df.loc[:,'Open'].rolling(window=ventana).std()
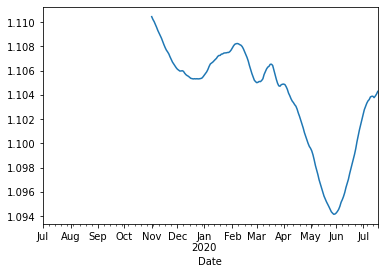
Vemos average «suaviza» la gráfica, caractarística principal de las medias móviles
df['average'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fc532fc40d0>
La desviación estándar nos da un valor en absoluto, y creo que el valor porcentual respecto a la media nos da un valor más intuitivo sobre las variaciones de los tipos de cambio:
df['std_pct'] = df['std'] / df['average']
df['std_pct'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fc53310c950>

Vemos en el gráfico anterior como ha variado durante esta primavera con las turbulencias del Covid:
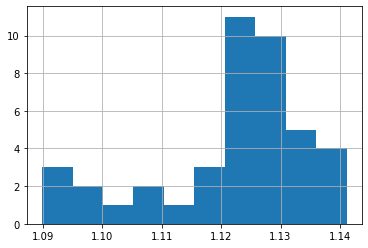
Añadimos un gráfico con el histógrama de los datos de los últimos sesenta días:
df[df['Close'].index>hoy_menos(60)]['Open'].hist(bins=10)
<matplotlib.axes._subplots.AxesSubplot at 0x7fc532f760d0>
Durante la preparación del trabajo pensé que esa medida de varianza de los datos del pasado podrían ser un indicativo de que nos va a ocurrir en el futuro, y para poder medir bien esa adecuación preparé la siguiente función que genera un ratio de cuantas muestras de los próximos 50 días a una fecha dada se saldrían del intervalo de «confianza»..es decir, si asumimos una desviación estándar como zona de confort más menos sobre el valor de ese día : ¿cuantas muestras se nos habrían escapado?.
La he preparado para ser añadida como una columna más, con una función apply
def calcula_out(x,coeficiente):
'''Calcula el numero de muestras del intervalo fecha del resgistro más 60 días
x: row del pandas
coeficiente: multiplicador de la desviación estandard, este numero ensancha o estrecha el intervalo de
confianza'''
panda=df.loc[x.name:x.name+timedelta(days=60)]
n_dias=panda.shape[0]
valor_sup=x['Open']+x['std']*coeficiente
valor_inf = x['Open']-x['std']*coeficiente
days_out=(panda['Open'] < (valor_inf)).sum() + (panda['Open'] > (valor_sup)).sum()
#print (x.name,days_out,n_dias)
return (days_out/n_dias)
df['tail']=df.apply(calcula_out,args=[1.0],axis=1)
Y haciendo pruebas pensé que sería interesante calcular esosoutliersfuera de una banda defininida con valores absolutos y no como función de la variación estandard:
def calcula_out_n(x,coeficiente):
panda=df.loc[x.name:x.name+timedelta(days=60)]
n_dias=panda.shape[0]
valor_sup=x['Open']*(1+coeficiente)
valor_inf = x['Open']*(1-coeficiente)
days_out=(panda['Open'] < (valor_inf)).sum() + (panda['Open'] > (valor_sup)).sum()
#print (x.name,days_out,n_dias)
return (days_out/n_dias)
df['tail_n']=df.apply(calcula_out_n,args=[0.05],axis=1)
Por último vamos a crear un pandasauxiliar en el que vamos a añadir como filas todos aquellos valores diarios con respecto a todos los días:
df2=pd.DataFrame()
for i in df.index:
df1 = df.loc[i:i+timedelta(days=60)]
panda=df1.reset_index()
panda['Date_ref']=i
panda['ratio_open']=abs(1-panda['Open']/df1.loc[i]['Open'])
df2=pd.concat([df2,panda],ignore_index=True)
Es decir: cojamos un día determinado, 15 de Mayo de 2020 por ejemplo:
df2.loc[df2['Date_ref'] == '2020-05-15']
| Date | Open | High | Low | Close | Currency | average | std | std_pct | tail | tail_n | Date_ref | ratio_open | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9985 | 2020-05-15 | 1.0805 | 1.0851 | 1.0789 | 1.0816 | USD | 1.096006 | 0.014989 | 0.013676 | 0.837209 | 0.023256 | 2020-05-15 | 0.000000 |
| 9986 | 2020-05-18 | 1.0816 | 1.0927 | 1.0799 | 1.0913 | USD | 1.095662 | 0.014961 | 0.013654 | 0.866667 | 0.088889 | 2020-05-15 | 0.001018 |
| 9987 | 2020-05-19 | 1.0913 | 1.0977 | 1.0901 | 1.0923 | USD | 1.095416 | 0.014846 | 0.013553 | 0.818182 | 0.000000 | 2020-05-15 | 0.009995 |
| 9988 | 2020-05-20 | 1.0928 | 1.1000 | 1.0918 | 1.0979 | USD | 1.095191 | 0.014729 | 0.013449 | 0.837209 | 0.000000 | 2020-05-15 | 0.011384 |
| 9989 | 2020-05-21 | 1.0979 | 1.1010 | 1.0936 | 1.0950 | USD | 1.095000 | 0.014579 | 0.013314 | 0.809524 | 0.000000 | 2020-05-15 | 0.016104 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 10023 | 2020-07-08 | 1.1273 | 1.1352 | 1.1262 | 1.1330 | USD | 1.103619 | 0.019807 | 0.017947 | 0.000000 | 0.000000 | 2020-05-15 | 0.043313 |
| 10024 | 2020-07-09 | 1.1329 | 1.1372 | 1.1279 | 1.1283 | USD | 1.103833 | 0.020019 | 0.018136 | 0.000000 | 0.000000 | 2020-05-15 | 0.048496 |
| 10025 | 2020-07-10 | 1.1285 | 1.1326 | 1.1255 | 1.1300 | USD | 1.103887 | 0.020079 | 0.018189 | 0.000000 | 0.000000 | 2020-05-15 | 0.044424 |
| 10026 | 2020-07-13 | 1.1300 | 1.1375 | 1.1297 | 1.1342 | USD | 1.103894 | 0.020089 | 0.018198 | 0.000000 | 0.000000 | 2020-05-15 | 0.045812 |
| 10027 | 2020-07-14 | 1.1343 | 1.1409 | 1.1324 | 1.1398 | USD | 1.103780 | 0.019883 | 0.018014 | 0.000000 | 0.000000 | 2020-05-15 | 0.049792 |
43 rows × 13 columns
vemos que se dispone de 43 días, indicados por la columna Date (son 43 días hábiles en ese periodo de 60 días naturales) y cada uno nos muestra los valores absolutos de ese días y una columna que hemos añadido ratio_openque nos indica la variación del valor de cambio de ese día Daterespecto a la fecha de referencia Date_ref
Gráficos
Preparamos aquí una imagen con dos subgráficos de dos curvas cada uno:
def format_y(value, tick_number):
return '{:.1%}'.format(value)
def format_y_2(value, tick_number):
return '{:.1%}'.format(value)
f = plt.figure(figsize=(15,10))
f.subplots_adjust(hspace=.5, wspace=.5)
color='navy'
ticks_meses=[2,4,6,8,10,12]
axe=f.add_subplot(2,1,1)
#axe.grid(which='both')
#axe.set_title('Total España',size=20)
axe.set_title('Varianza porcentual de los últimos 90 días y dispersión de los siguientes 60 días',color=color,size=20)
#sns.lineplot(t, data1, ax=axe,color='blue',linewidth=2)
sns.set(style="darkgrid")
sns.lineplot(x='Date',y='std_pct',data=df.reset_index(),ax=axe,color=color,linewidth=5)
axe.xaxis.set_major_locator(mdates.YearLocator(1))
axe.xaxis.set_minor_locator(mdates.MonthLocator())
majorFmt = mdates.DateFormatter('%b/%Y')
minorFmt = mdates.DateFormatter('%b')
axe.xaxis.set_major_formatter(majorFmt)
axe.xaxis.set_minor_formatter(minorFmt)
axe.yaxis.set_major_formatter(ticker.FuncFormatter(format_y))
axe.tick_params(axis='y', labelcolor=color,labelsize=16)
axe.tick_params(axis='x',which='major',labelcolor=color,labelsize=20,pad=20)
axe.tick_params(axis='x',which='minor',labelcolor=color,labelsize=14)
axe.set_xlabel('')
axe.set_ylabel('')
ax2 = axe.twinx() # instantiate a second axes that shares the same x-axis
ax2.set_ylabel('Desviacion en porcentaje', color=color,size=15)
ax2.grid(which='both')
sns.lineplot(x='Date',y='tail',data=df.reset_index(),ax=ax2,color='red',linewidth=2)
ax2.xaxis.set_major_locator(mdates.YearLocator(1))
ax2.xaxis.set_minor_locator(mdates.MonthLocator(ticks_meses))
ax2.xaxis.set_major_formatter(majorFmt)
ax2.xaxis.set_minor_formatter(minorFmt)
ax2.yaxis.set_major_formatter(ticker.FuncFormatter(format_y))
ax2.tick_params(axis='y', labelcolor='red',labelsize=16)
ax2.set_xlabel('')
ax2.set_ylabel('')
ax4=f.add_subplot(2,1,2)
#ax4.grid(False,which='both')
#axe.set_title('Total España',size=20)
ax4.set_title('Varianza porcentual de los últimos 90 días y dispersión de los siguientes 60 días',color=color,size=20)
#sns.lineplot(t, data1, ax=axe,color='blue',linewidth=2)
sns.lineplot(x='Date_ref',y='ratio_open',data=df2,ax=ax4,color=color,linewidth=1)
ax4.xaxis.set_major_locator(mdates.YearLocator(1))
ax4.xaxis.set_minor_locator(mdates.MonthLocator(ticks_meses))
majorFmt = mdates.DateFormatter('%b/%Y')
minorFmt = mdates.DateFormatter('%b')
ax4.xaxis.set_major_formatter(majorFmt)
ax4.xaxis.set_minor_formatter(minorFmt)
ax4.yaxis.set_major_formatter(ticker.FuncFormatter(format_y))
ax4.tick_params(axis='y', labelcolor=color,labelsize=16)
ax4.tick_params(axis='x',which='major',labelcolor=color,labelsize=20,pad=20)
ax4.tick_params(axis='x',which='minor',labelcolor=color,labelsize=14)
ax4.set_xlabel('')
ax4.set_ylabel('')
ax5=ax4.twinx()
#axe.grid(which='both')
#axe.set_title('Total España',size=20)
ax5.set_title('Varianza porcentual de los últimos 90 días y dispersión de los siguientes 60 días',color=color,size=20)
#sns.lineplot(t, data1, ax=axe,color='blue',linewidth=2)
sns.lineplot(x='Date',y='Open',data=df.reset_index(),ax=ax5,color='olive',linewidth=5,alpha=.2)
ax5.grid(False,which='both')
ax5.xaxis.set_major_locator(mdates.YearLocator(1))
ax5.xaxis.set_minor_locator(mdates.MonthLocator(ticks_meses))
majorFmt = mdates.DateFormatter('%b/%Y')
minorFmt = mdates.DateFormatter('%b')
ax5.xaxis.set_major_formatter(majorFmt)
ax5.xaxis.set_minor_formatter(minorFmt)
ax5.yaxis.set_major_formatter(ticker.FuncFormatter(ticker.FormatStrFormatter('%4.2f')))
ax5.tick_params(axis='y', labelcolor='olive',labelsize=16)
ax5.tick_params(axis='x',which='major',labelcolor='olive',labelsize=20,pad=20)
ax5.tick_params(axis='x',which='minor',labelcolor='olive',labelsize=14)
ax5.set_xlabel('')
ax5.set_ylabel('')
f.tight_layout()

Como se puede observar los resultados durante esta primavera habrían sido muy peligrosos, cosa lógica con la volativilidad que tuvo el cambio. Vemos en la línea roja (tail) que muchos días están fuera del intervalo de confianza. La curva azul de la segunda gráfica nos indica el rango de desviación que el cambio tiene en los siguientes 60 días (son los datos que hemos conseguido con el pandas df2
He preparado un código específico para el segundo gráfico:
def format_y(value, tick_number):
return '{:.1%}'.format(value)
def format_y_2(value, tick_number):
return '{:.2f}'.format(value)
f = plt.figure(figsize=(10,5))
f.subplots_adjust(hspace=.5, wspace=.5)
color='navy'
ticks_meses=[2,4,6,8,10,12]
ax4=f.add_subplot(1,1,1)
#ax4.grid(False,which='both')
#axe.set_title('Total España',size=20)
ax4.set_title('Cambio dolar por euro y rango de variación de cambios de los siguientes 60 días',
y=-0.3,color=color,size=20)
#sns.lineplot(x='Date_ref',y='dato',data=df2,ax=ax4,color=color,linewidth=1)
sns.lineplot(x='Date',y='Open',data=df.reset_index(),ax=ax4,color='olive',linewidth=3,alpha=.4)
ax4.xaxis.set_major_locator(mdates.YearLocator(1))
ax4.xaxis.set_minor_locator(mdates.MonthLocator(ticks_meses))
majorFmt = mdates.DateFormatter('%b/%Y')
minorFmt = mdates.DateFormatter('%b')
ax4.xaxis.set_major_formatter(majorFmt)
ax4.xaxis.set_minor_formatter(minorFmt)
ax4.yaxis.set_major_formatter(ticker.FuncFormatter(format_y_2))
ax4.tick_params(axis='y', labelcolor='olive',labelsize=25)
ax4.tick_params(axis='x',which='major',labelcolor='olive',labelsize=25,pad=20)
ax4.tick_params(axis='x',which='minor',labelcolor='olive',labelsize=20)
ax4.set_xlabel('')
ax4.set_ylabel('')
ax5=ax4.twinx()
#axe.grid(which='both')
#axe.set_title('Total España',size=20)
#sns.lineplot(t, data1, ax=axe,color='blue',linewidth=2)
#sns.lineplot(x='Date',y='Open',data=df.reset_index(),ax=ax5,color='olive',linewidth=5,alpha=.4)
sns.lineplot(x='Date_ref',y='ratio_open',data=df2,ax=ax5,color=color,linewidth=1)
ax5.grid(False,which='both')
ax5.xaxis.set_major_locator(mdates.YearLocator(1))
ax5.xaxis.set_minor_locator(mdates.MonthLocator(ticks_meses))
#ax5.yaxis.set_major_locator([1,2,3])
loc = ticker.MultipleLocator(0.5) # this locator puts ticks at regular intervals
ax5.yaxis.set_major_locator(ticker.FixedLocator([0,0.01,0.02,0.03,0.04,0.05]))
majorFmt = mdates.DateFormatter('%b/%Y')
minorFmt = mdates.DateFormatter('%b')
ax5.xaxis.set_major_formatter(majorFmt)
ax5.xaxis.set_minor_formatter(minorFmt)
ax5.yaxis.set_major_formatter(ticker.FuncFormatter(format_y))
ax5.tick_params(axis='y', labelcolor=color,labelsize=25)
ax5.tick_params(axis='x',which='major',labelcolor=color,labelsize=25,pad=20)
ax5.tick_params(axis='x',which='minor',labelcolor=color,labelsize=20)
#ax5.set_xlabel('')
ax5.set_ylabel('')
f.tight_layout()
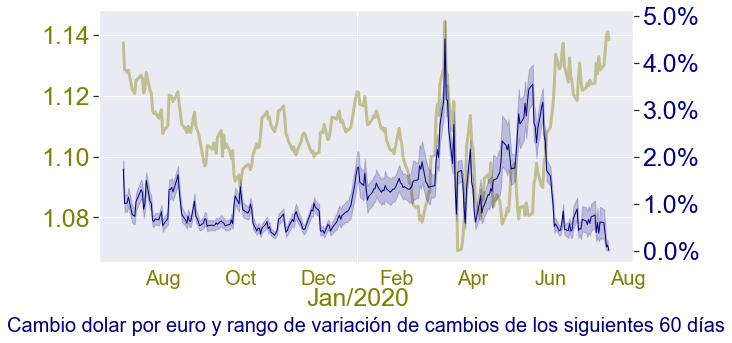
Podemos observar que la azul anticipa las variaciones futuras, obvio!!..pues así está calculado, no caigamos en la y trampa de pensar que en verdad anticipa!..es solo una representación gráfica de, a posterior, que riesgo habríamos corrido en una transación con cambio euro dolar cerrado. Así podemos ver que durante Febrero, Marzo la volatibilidad se disparó. Actualmente, y aparentemente, estamos en una zona de estabilidad, también influida logicamente por la falta de muestras, pues no se dispone de la ventana de 60 días.
Y ahí está la oportunidad para un futuro trabajo: ¿como predecimos el riesgo que corremos al marcar hoy un determinado cambio?..manos a la obra!
Este notebook está disponible en https://github.com/mharias/stock
