
Introducción a la discusión
En este ejercicio vamos a estudiar como se relacionan modelos a priori estancos como un simple Bernouilli con la distribución exponencial. Como pensando en sucesos singulares, que se repiten en el tiempo, podemos llegar a entender la distribución de los tiempos de espera entre esos sucesos. Empecemos…
Supongamos que estamos observando un suceso aleatorio, cuyo resultado es binario, digamos 0 ó 1, con una probablidad de éxito p. Este suceso se repite a lo largo del tiempo. Y podemos medir cuantos sucesos tienen éxito en un determinado espacio temporal. Y hemos de dar por hecho que no es posible que se ejecuten dos sucesos en el mismo instante de tiempo. Esta aproximación la podemos asumir «estirando» la escala de tiempo. Buscaríamos una unidad de tiempo más pequeña que consiga que esos sucesos estén separados. Por ejemplo : si el suceso que estamos estudiando es «un coche pasa por este determinado carril» y usamos como unidad de tiempo un minuto nos encontraremos, con alta probabilidad, que en determinados minutos pasan dos o más vehículos, luego recortaríamos la franja de tiempo a los segundos necesarios y suficientes para que no nos enfrentáramos con esa situación.
Empezamos la observación
Nos abstraemos del valor absoluto del intervalo de tiempo, nos da lo mismo si es un 
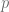
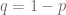

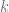
Este experimento se puede modelar como una binomial de

Y ya lo tenemos!…sabemos el número de experimentos que realizamos,
..y si no sabemos cuantos experimentos se están realizando?
Por un momento pensemos en el ejemplo del coche, ¿hemos elegido bien el nº de experimentos?…es posible que se solapen? ¿sabemos cual es la probabilidad que hemos denominado de éxito?, ¿y si solo conocemos el ratio de éxito en un determinado tiempo?. Como por ejemplo: el nº de coches por hora….en este caso conoceríamos una tasa 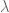
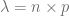
Hagamos a continuación este cambio: apliquemos esta última expresión al resultado de la Binomial.

Y ahora, recordando que no conocemos ni 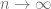
![\lim\limits_{n\to\infty} P(X=k) = \lim\limits_{n\to\infty} {n \choose k}p^{k} \times (1-p)^{(n-k)} = \lim\limits_{n\to\infty} \left[ \dfrac{n!}{k!\,(n-k)!}\left (\dfrac{\lambda}{n}\right)^{k}\left(1-\dfrac{\lambda}{n}\right)^{(n-k)} \right]](https://s0.wp.com/latex.php?latex=%5Clim%5Climits_%7Bn%5Cto%5Cinfty%7D+P%28X%3Dk%29+%3D+%5Clim%5Climits_%7Bn%5Cto%5Cinfty%7D+%7Bn+%5Cchoose+k%7Dp%5E%7Bk%7D+%5Ctimes+%281-p%29%5E%7B%28n-k%29%7D+%3D++%5Clim%5Climits_%7Bn%5Cto%5Cinfty%7D+%5Cleft%5B+%5Cdfrac%7Bn%21%7D%7Bk%21%5C%2C%28n-k%29%21%7D%5Cleft+%28%5Cdfrac%7B%5Clambda%7D%7Bn%7D%5Cright%29%5E%7Bk%7D%5Cleft%281-%5Cdfrac%7B%5Clambda%7D%7Bn%7D%5Cright%29%5E%7B%28n-k%29%7D+%5Cright%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
podemos sacar de límite las expresiones no afectadas por 

![\lim\limits_{n\to\infty} P(X=k) = \dfrac{\lambda^k}{k!} \lim\limits_{n\to\infty} \left[ \dfrac{n!}{(n-k)!}\left( \dfrac{1}{n^k}\right) \left(1-\dfrac{\lambda}{n}\right)^{n} \left(1-\dfrac{\lambda}{n}\right)^{-k} \right]](https://s0.wp.com/latex.php?latex=%5Clim%5Climits_%7Bn%5Cto%5Cinfty%7D+P%28X%3Dk%29+%3D+%5Cdfrac%7B%5Clambda%5Ek%7D%7Bk%21%7D+%5Clim%5Climits_%7Bn%5Cto%5Cinfty%7D++%5Cleft%5B+%5Cdfrac%7Bn%21%7D%7B%28n-k%29%21%7D%5Cleft%28+%5Cdfrac%7B1%7D%7Bn%5Ek%7D%5Cright%29+%5Cleft%281-%5Cdfrac%7B%5Clambda%7D%7Bn%7D%5Cright%29%5E%7Bn%7D++%5Cleft%281-%5Cdfrac%7B%5Clambda%7D%7Bn%7D%5Cright%29%5E%7B-k%7D+%5Cright%5D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Sabemos que, en general, y si estos existen, el límite de un producto de funciones es equivalente al producto de los límites. Luego vamos a descomponer esa expresión en tres funciones y calcularemos, entonces, el límite de cada una:
Empezamos por 

Podemos comprobar que hay igual número de terminos de 
Vamos a por la segunda expresión:

Vamos a realizar una sustitución de variable para resolver este límite. Vamos a llamar 

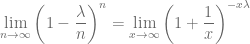


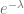
Finalmente calculemos el valor de la tercera expresión : 
Aplicando los tres resultados anteriores llegamos a la siguiente expresión: 
Hemos pensado en como modelar un determinado suceso aleatorio, partiendo de un nº conocido de sucesos
¿Y si nos preguntamos cual será el tiempo entre esos sucesos? ¿cómo calculamos el tiempo entre cada paso de coches?
De Poisson a la Exponencial

De la expresión anterior: 
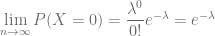
¿Qué nos indica este número?, es la probabilidad de que no pase ningún coche en el intervalo de tiempo al que hace referencia la tasa 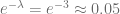

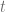

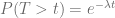
La expresión 

Recordemos que hemos empezado con un suceso Bernouilli con probabilidad de éxito
Este cadena entre modelos es lo que más me ha gustado durante la preparación de este trabajo. Siempre pensé en modelos «estancos» y hemos visto que no siempre es así, y como modelos aparentemente inconexos no dejan de ser casos particulares, o relacionados en la medida de algún parámetro.
…memoryless?
En un determinado momento he mencionado que el proceso de Poisson «no tiene memoria», ¿qué significa eso?: que el tiempo de espera hasta observar un suceso exitoso es independiente del tiempo que llevamos observando, del tiempo que llevamos esperando a que suceda.
Matemáticamente se puede expresar tal que: 
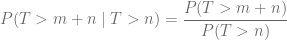

Y es esta una de las característas que hacen difícil modelas sucesos como poisonianos. Un ejemplo muy utilizado es el de llegada de autobús a una parada: el tiempo de espera es independiente del momento en el que lleguemos: pues no!..los autobuses tienen una determinada cadencia de salida, y por muchos eventos aleatorios que vayan sucediendo, esa cadencia se va manteniendo a lo largo de la jornada.
A lo largo de este trabajo he intentado mostrar como llegar a las expresiones de las distribuciones de Poisson y Exponencial reflexionando sobre los sucesos aleatorios imples que la componen. Y como, en particula,r, la distribución de Poisson es una Binomial en la que n tiende a infinito.
