Introducción..un poco de teoría
En este trabajo vamos a estudiar las dos aproximaciones más conocidas en los métodos de inferencia estadística: el método bayesiano y el frecuentista. Un búsqueda rápida en Google confirma el gran número de interesantes discusiones al respecto. Personalmente me decanto por el Bayesiano, al final de este trabajo explicaré por qué.

Según nos indica el profesor Wasserman en su libro «All of Statistics» el método frecuentista se apoya en tres postulados:
- La probabilidad se entiende como frecuencias relativas, y son propiedades objetivas del mundo real. Un proceso o suceso tiene sus probabilidades que lo parametrizan, que podemos llegar a conocer o no, pero existen.
- Los parametros que definen el modelo estadístico (
y
en una beta o la media,
y la varianza,
en una normal) son números constantes y, por lo general, desconocidos. Y puesto que no fluctúan no se le pueden asociar características de naturaleza estadística (no existe una media o una varianza de la estimación de la media.
- Los procedimientos estadísticos se han de diseñar para tener propiedades que se mantengan en el largo plazo. Esto significa que un intervalo de confianza del 95% debería contener el valor real del parámetro en cuestión en, al menos, un 95% de las ocasiones.
El frecuentista asocia un numero al parámetro que describe el suceso, y ese número no cambia. No fluctúa.
Como contrapartida, el método Bayesiano se basa en estos postulados:
- La probabilidad describe un cierto grado de creencia, y no está relacionada con la frecuencia. Este principio nos permiter realizar aseveraciones sobre múltiples situaciones o escenarios, y no solo sobre conjuntos de datos sujetos a variación estadística. Podemos, como ejemplo, decir que “la probabilidad de que mi amigo haya visto un anuncio de TV en el último día del año es del 55%”..esta afirmación no esta relacionada con frecuencia, simplemente refleja mi grado de creencia en esa afimación.
- Por tanto podemos hacer juicios probabilísticos sobre los parámetros de una determinada distribución de los resultados de un suceso estadístico.
- Y los podemos hacer puesto que habremos sido capaces de calcular la función de distribución de probabilidad del parámetro. Podremos calcular su moda, media o estimar intervalos.
Hemos hablado de “grados de creencia” que nos evoca subjetividad en vez de la objetividad que pensamos que es indiscutible cuando hablamos de Estadística o Matemáticas, pero veremos como esa subjetividad, en muchas ocasiones, no deja de ser la aceptación de falta de conocimiento previo sobre el suceso aleatorio que estamos estudiando. Me atrevo a decir que el método bayesiano, rigurosamente aplicado, nos permite aplicar y evaluar objetivamente nuestra “ignorancia” sobre un suceso.
Y nos podríamos preguntar si esta diferente aproximación trae, al final, diferentes resultados: y la respuesta es que sí. Podríamos pensar que independientemente de como nos aproximemos al problema la realidad es una sola, y única. Pero veamos un experimento en el que dependiendo de como nos aproximemos obtendremos un resultado u otro. Finalmente simularemos el suceso con código python para comprobar que método se aproxima más a la realidad. Empecemos….

El problema del juego entre Ana y Bruno
Ana y Bruno (¡nuestra versión española de los anglosajones Alice y Bob!) están compitiendo en un juego. Se van jugando rondas y el primero que llegue a 6 puntos gana, y en este momento Ana gana a Bruno por 5 puntos a 3.
Esa es la única información de la que disponemos, y el problema que hemos de resolver es: ¿qué posibilidad tiene Bruno de ganar el juego?
El primero que llegue a seis puntos gana la partida, y Ana va ganando a Bruno por 5 puntos a 3. ¿Qué posibilidades tiene Bruno de ganar?
El enfoque frecuentista
¿Qué podemos inferir de la escasa información que nos han dado?..
Intuitivamente podríamos decir que la estimación de la probabilidad de que Ana gane una partida es 5/8, pero veamos como podemos confirmar matemáticamente esa intuición.
Podemos asumir que estamos antes una distribución binomial de la que tendremos que estima la probabilidad 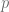

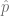
Este método nos permite calcular el parámetro
Que equivale a esta expresión 
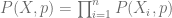
Para calcular este argumento 



En esta última igualdad asumimos que de las n partidas Ana ha ganado k, 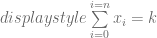
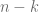
Ahora aplicamos logaritmo a la multiplicación y pasamos los exponentes a multiplicandos del logaritmo:


Es decir, tal como habíamos previsto, el valor de P, que denominamos

El enfoque Bayesiano
Recordemos la famosa ecuación de la estadística bayesiana:
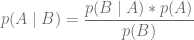
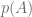



Como aplicamos esta aproximación al problema concreto en el que estamos trabajando?.
Definamos en primer lugar las notaciones:
se refiere a “Ana gana el juego”, ha llegado a los 6 puntos
se refiere a “Bruno gana el juego”
- D son los datos observados actuales, que viene ser los resultados actuales, luego
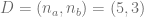
Siguiendo con la terminología bayesiana lo que queremos calcular es 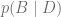
Como quiera que no conocemos 


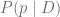
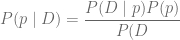



En este punto veamos cada uno de los términos de la integral:
: este término se refiere a la probabilidad de que Bruno gane la partida, si la probabilidad de que gane Ana es
. Este término indica la probabilidad de llegar a un resultado D partiendo de una probabilidad
. Este término $latex \binom {8}{5} se anula al aparecer tanto el denominador como denominador.
- Y finalmente P(p), que recordemos que el prior dentro del modelo bayesiano. Y que sabemos «a priori» de la probabilidad

![P(p) \propto 1 \forall p\in [0,1]](https://s0.wp.com/latex.php?latex=P%28p%29+%5Cpropto+1++%5Cforall+p%5Cin+%5B0%2C1%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Teniendo en cuenta estas consideraciones podemos escribir nuestra expresión como:

..que no deja de ser una función beta, o euleriana de primera clase,

Nos vamos a ayudar de un poco de código para resolver esta integral. En la integral superior 


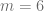

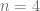
from scipy.special import beta
ratio_betas = beta(7, 6) / beta(4, 6)
print("P(B|D) = {0:.2f}".format(ratio_betas))
P(B|D) = 0.09
Es decir, Bruno tiene 1 contra 11 posibilidades de ganar la partida.
Nos hemos encontrado con un problema al que nos aproximamos de dos maneras diferentes y que nos da dos resultados diferentes.
Recordemos que en el caso frecuentista asumimos que la función de probabilidad es una binomial, calcula la
En el caso bayesiano aplicamos lo que sabemos, que es que no sabemos nada del parámetro 
¿Cuál es el resultado correcto?, apliquemos fuerza bruta antes de tomar esa decisión. Con la ayuda de un poco de código python simulemos juegos con p aleatoria, filtremos aquellos en los que el resultado es tal que (Ana=5, Bruno=3), veamos como acabaron esos casos y finalmente calculemos el ratio de los ganados por Bruno frente al total. Compararemos ese resultado con los calculados bajo los dos modelos anteriores.
Simulación con método MonteCarlo

import numpy as np
from scipy.stats import binom
n_partidas = 50000
n_rondas_partida = 11
gana_Ana_ahora = 5
matriz_partidas = np.ndarray([n_partidas,n_rondas_partida])
i=0
while i < n_partidas:
p = np.random.random()
r = binom.rvs(1,p,size=n_rondas_partida)
if r[:8].sum() == gana_Ana_ahora:
#print(i)
matriz_partidas[i,:] = r
i+=1
test = lambda x: x.sum() == gana_Ana_ahora
bruno_gana = np.apply_along_axis(test,1,matriz_partidas).sum()
print("P(B|D) = {0:.4f}".format(bruno_gana/n_partidas))
P(B|D) = 0.0914
Este código genera 50.000 partidas, de 11 rondas cada una, en las que, en la ronda 8 Ana va ganando por 5 juegos a 3. Y posteriormente chequea cuantas de esas partidas ha ganado Bruno, que equivale a decir que al final de la partida, tras 11 rondas, Ana sigue teniendo 5 puntos puesto que significa que Bruno habría ganado las tres últimas.
Y vemos que el porcentaje de partidas es aproximadamente igual al resultado que cálculamos con el método bayesiano.
Conclusiones
En el código anterior hay una línea fundamental . Dentro del while podemos ver que actualizamos la probabilidad que aplicamos a la función binomial siguiente. Esto significa que cada «partida» tiene una probabilidad diferente, que se alinea con el criterio que hemos aplicado en el modelo Bayesiano de no saber apriori nada del modelo. Sin embargo en el frecuentista hemos asumido, en base a la observación, que la
«…son números constantes y, por lo general, desconocidos. Y puesto que no fluctúan no se le pueden asociar características de naturaleza estadística (no existe una media o una varianza de la estimación de la media.»
El resultado frecuentista nos indica que de todas las partidas con probabilidad de que Ana gane un juego 
Mi opinión es que no hay una respuesta correcta «a priori», pero sin ninguna duda me siento mucho más confortable con el modelo Bayesiano. Es un modelo en el que no hemos hecho la asunción de que todas las partidas tienen la misma
Referencias:
[All of Statistics, A Concise Course in Statistical Inference, Larry Wasserman]
[http://jakevdp.github.io/blog/2014/06/06/frequentism-and-bayesianism-2-when-results-differ/ Jake Van de Plass]
